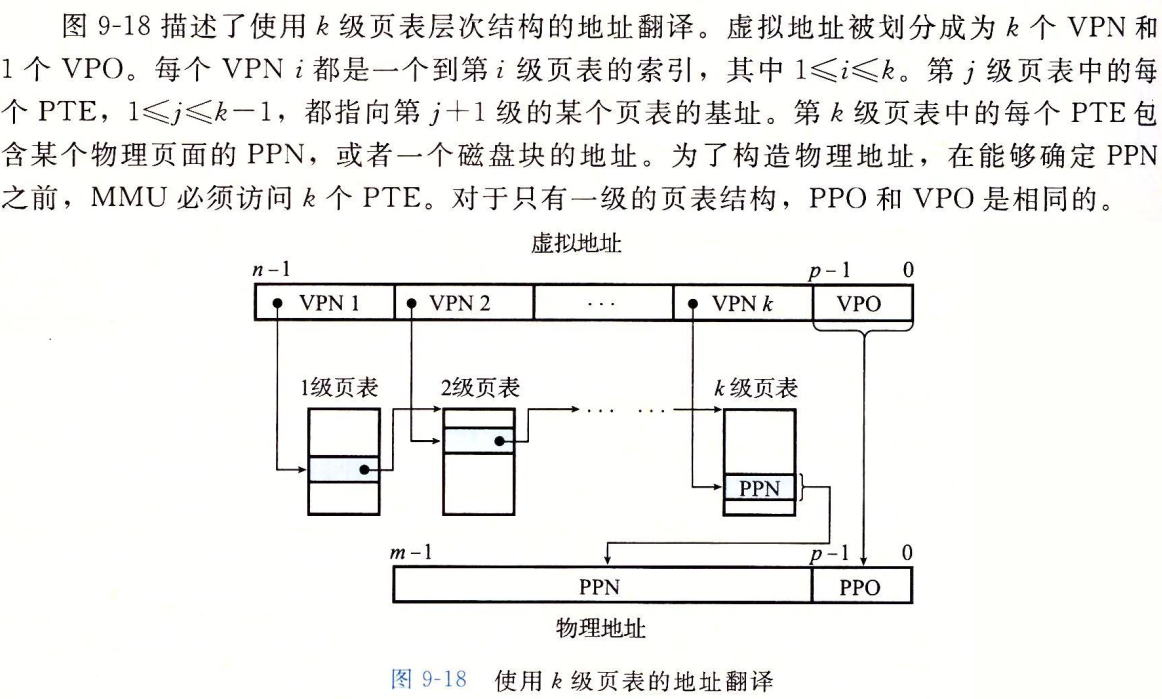
Address Translation
Overview motivation, designed-path and research-trend
1 | stateDiagram-v2 |
虚拟地址和物理地址
- 在现代的操作系统中,为了让多任务的程序能方便的运行在操作系统上,需要完成的一个很重要的抽象是「每个程序有自己的地址空间,且地址空间范围(虚拟地址长度决定)是一样的」。
- 程序自身看到的地址空间,就是虚拟内存。而访问虚拟内存的地址就是虚拟地址(Virtual Address),与之对应的是物理地址(Physical Address)。
- 这样的设计会导致上层的应用程序可能会访问同一个值相等的虚拟地址,所以操作系统需要做的就是替这些程序维护这个虚拟地址到物理地址的映射(页表)。甚者,为了统一和连贯,内核自己本身访问内存也将会通过虚拟地址。
!!! tip notate “VM make Physical Memory as a Cache”
Physical memory is a **cache for pages stored on disk**(1). In fact, it is a fully-associative cache in modern systems (a virtual page can potentially be mapped to any physical frame)[^29]
This is because caching is a **equal object mapping** technique. And page and frame is the equal object pair.
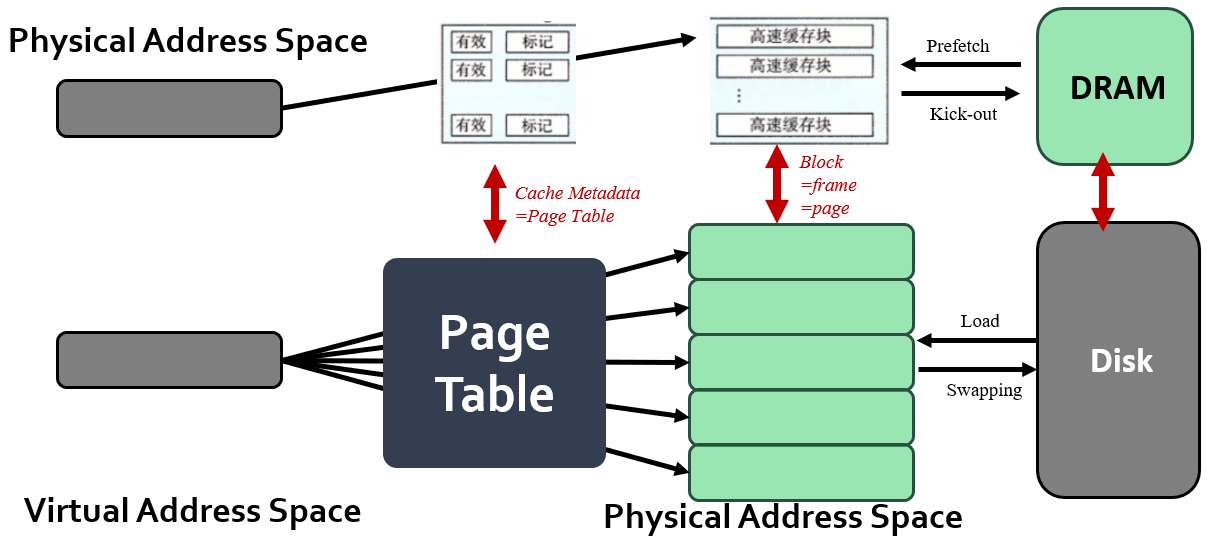
Similar caching issues exist as we have covered earlier:
- Placement: where and how to place/find a page in cache?
- Replacement: what page to remove to make room in cache?
- Granularity of management: large, small, uniform pages?
- Write policy: what do we do about writes? Write back?

- L1 cache for cache line in DRAM. Because block size is always cache line size.
??? failure annotate “Key Observation : Full associate VA2PA mapping is not necessary”
Paper NAT[^14] show that modern server workloads do not need a fully associative VM and can tolerate associativity ranging from direct-mapped(1) to 4-way associative.
Table II (left) shows the page conflict(2) rate as associativity varies. As shown, little associativity is enough to eliminate all page conflicts and match fully associative VM.
Table II (right) estimates the average memory access time (AMAT) increase due to page conflicts.

**MY DEDUCTION**: Antoher words, most apps's virtual space is focus in `8GB * 2 = 16GB`.
Table IV.
- `Total segments` represents the total number of virtual segments.
- `99% coverage` indicates the number of virtual segments required to cover 99% of the physical address space.
- `Largest segment` shows the fraction of the physical address space covered with the largest virtual segment.
- `Largest 32 segments` shows the fraction of the physical space covered with the largest 32 segments.
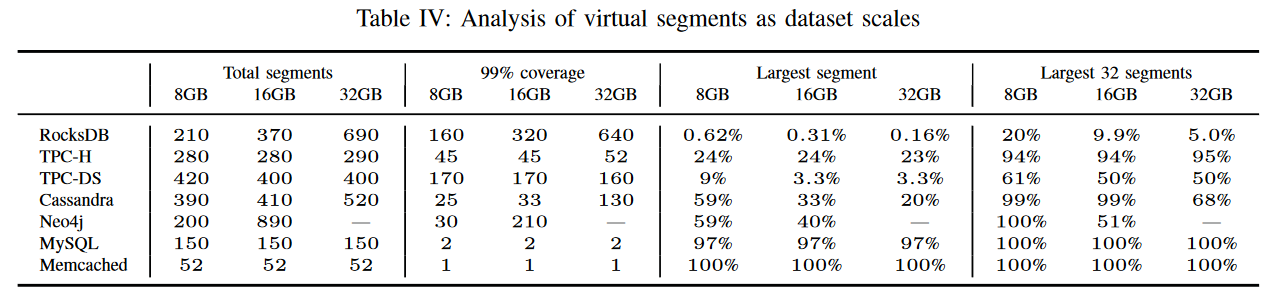
First, for some applications, such as MySQL and Memcached, a single large segment covers most of the physical memory, and therefore Direct map would eliminate most TLB misses
Third, although there could be hundreds of segments, the associativity requirements for 8GB dataset(Table II) indicate that associativity can be reduced to a small number. The reason is that although segments are not fully contiguous, the OS tends to cluster the segments (as shown in Figure 3), and therefore nearby segments do not conflict with each other.

- cache-like map to 8GB physical memory
- multiple virtual pages(high bits different) could map to the same physical frame, resulting in page conflicts.
Linux 虚拟内存系统
segmentation
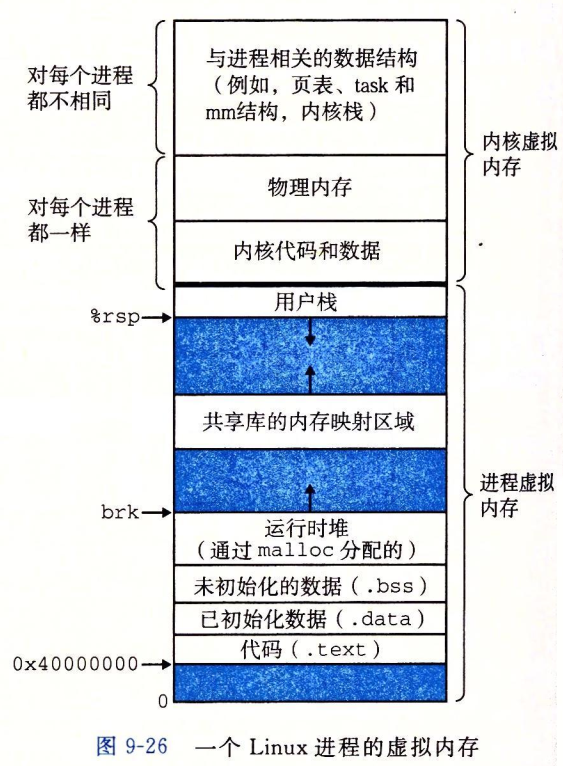
仔细分析 虚拟内存位于用户栈之上。
 { width=80% }
{ width=80% }
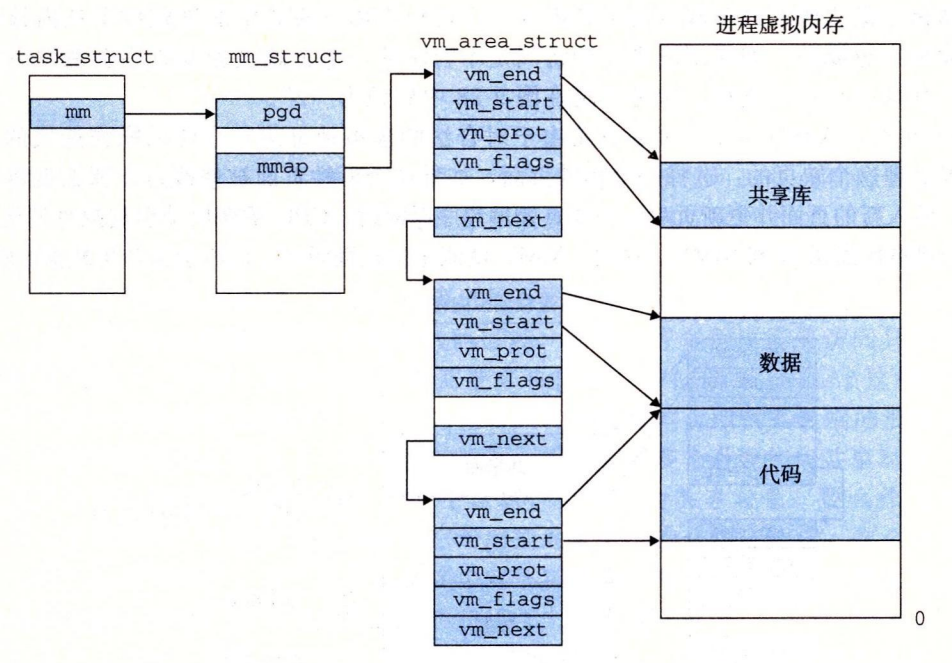
Linux 将虚拟内存组织成一些区域(也叫做段)的集合。一个区域(area)就是已经存在着的(已分配的)虚拟内存的连续片(chunk),这些页是以某种方式相关联的。例如,代码段、数据段、堆、共享库段,以及用户栈都是不同的区域。每个存在的虚拟页面都保存在某个区域中,而不属于某个区域的虚拟页是不存在的,并且不能被进程引用。
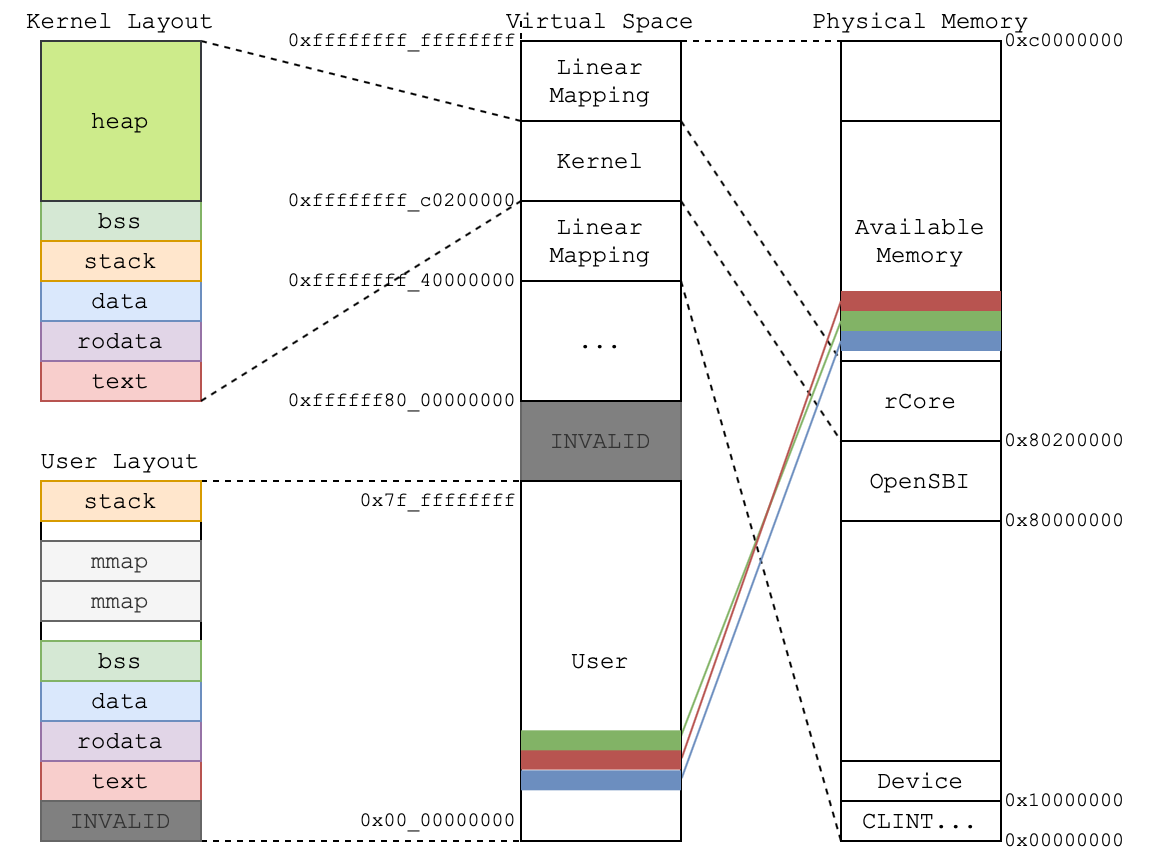
!!! note annotate “virtual address space layout of a Linux process”
Figure 3 shows the virtual address space layout of a Linux process, featuring six virtual segment groups:
1. the read-only segments, which consist of the binaries (`.text`) and globally visible constants (`.ro`);
2. the read-write segments, containing global variables (`.rw` and `.bss`);
3. the heap segment, which holds dynamically allocated objects;
4. the mmap segments, for objects allocated through the mmap syscall;
5. the stack segment;
6. and the kernel address space.
We assume only the dark-colored segments are visible to MPUs. The virtual address space that is not exposed to MPUs (e.g., the kernel space) still enjoys full associativity(1).

- Guess: kernel is used frequently.
 { width=80% }
{ width=80% }
一个具体区域的区域结构包含下面的字段:
- vm_start:指向这个区域的起始处。
- vm_end:指向这个区域的结束处。
- vm_prot:描述这个区域内包含的所有页的读写许可权限。
- vm_flags:描述这个区域内的页面是与其他进程共享的,还是这个进程私有的(还描述了其他一些信息)。
- vm_next:指向链表中下—区域结构。
段错误 与 非法操作
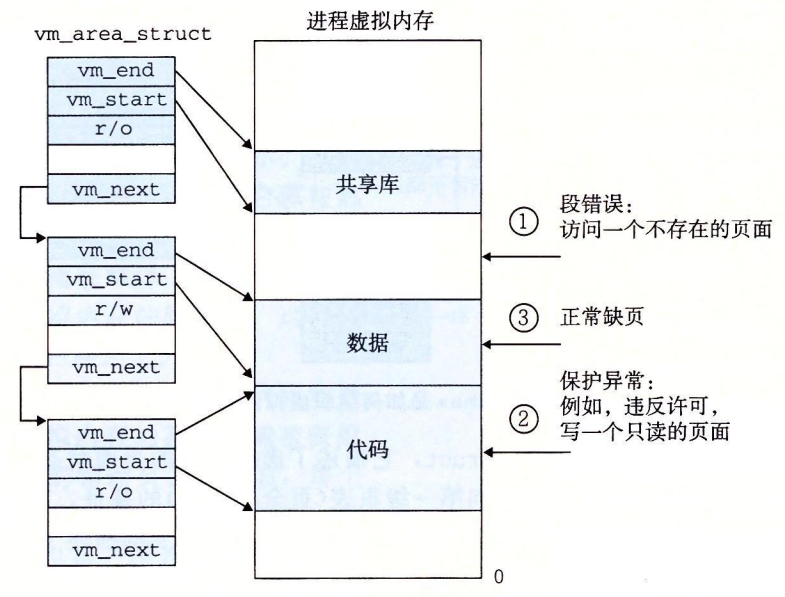
假设 MMU 在试图翻译某个虚拟地址 A 时,触发了一个缺页。这个异常导致控制转移到内核的缺页处理程序,处理程序随后就执行下面的步骤:
- 虚拟地址 A 是合法的吗?换句话说,A 在某个区域结构定义的区域内吗?为了回答这个问题,缺页处理程序搜索区域结构的链表,把 A 和每个区域结构中的 vm_start 和 vm_end 做比较。如果这个指令是不合法的,那么缺页处理程序就触发一个段错误,从而终止这个进程。这个情况在图 9-28 中标识为 “1”。
- 因为一个进程可以创建任意数量的新虚拟内存区域(使用在下一节中描述的 mmap 函数),所以顺序搜索区域结构的链表花销可能会很大。因此在实际中,Linux 使用某些我们没有显示出来的字段,Linux 在链表中构建了一棵树,并在这棵树上进行查找。
- 试图进行的内存访问是否合法?换句话说,进程是否有读、写或者执行这个区域内页面的权限?例如,这个缺页是不是由一条试图对这个代码段里的只读页面进行写操作的存储指令造成的?这个缺页是不是因为一个运行在用户模式中的进程试图从内核虚拟内存中读取字造成的?如果试图进行的访问是不合法的,那么缺页处理程序会触发一个保护异常,从而终止这个进程。这种情况在图 9-28 中标识为 “2”。
注意Segmentation Fault 只会在缺页时触发,声明 int A[10] , 访问 A[11] , 不一定会触发Segmentation Fault(段错误)
 { width=80% }
{ width=80% }
页表 数据结构
- Page table: table that stores virtual 2 physical page mappings lookup table used to translate
virtual page addressestophysical frame addresses (and find where the associated data is)[^29] - Page size: the mapping granularity of virtualphysical address spaces
,dictates the amount of data transferred from hard disk to DRAM at once
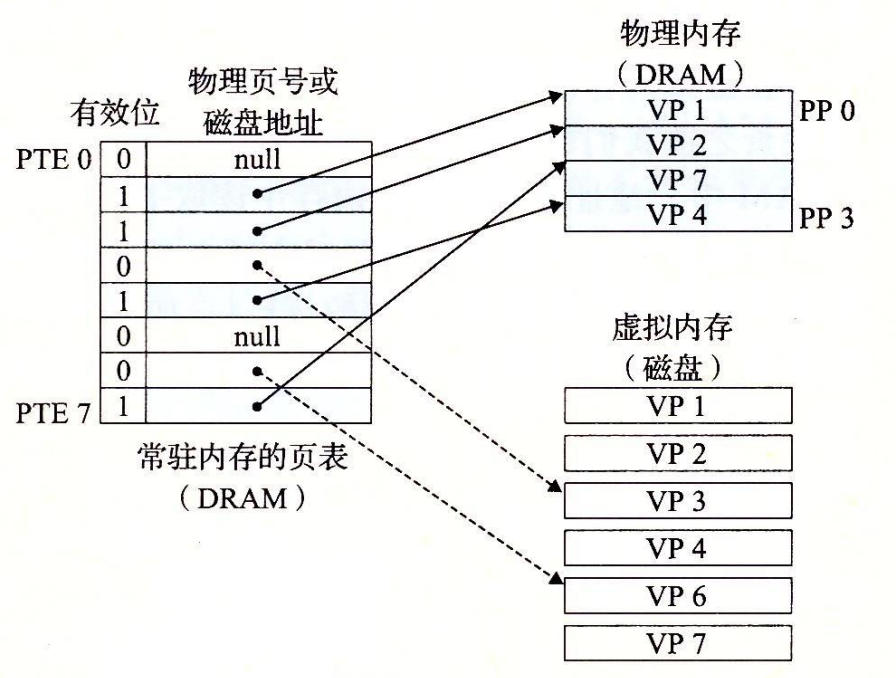
- 页表是记录每一虚拟页在内存中缓存的物理块页号。
- 每次地址翻译硬件将一个虚拟地址转换为物理地址时,都会读取页表。
页表的基本组织结构
- 页表就是一个页表条目(Page Table Entry,PTE)的数组。
- 虚拟地址空间(虚拟地址)中的每个页在页表中一个固定偏移量处都有一个 PTE。
- 简化来说,每个 PTE 是由一个有效位(valid bit)和一个 n 位地址字段组成的。
- 有效位表明了该虚拟页当前是否被缓存在 DRAM 中。
- 如果设置了有效位,那么地址字段就表示 DRAM 中相应的物理页的起始位置,这个物理页中缓存了该虚拟页。
- 如果没有设置有效位,那么一个空地址表示这个虚拟页还未被分配。否则,这个地址就指向该虚拟页在磁盘上的起始位置。
- 下图就是个示例
 { width=80% }
{ width=80% }
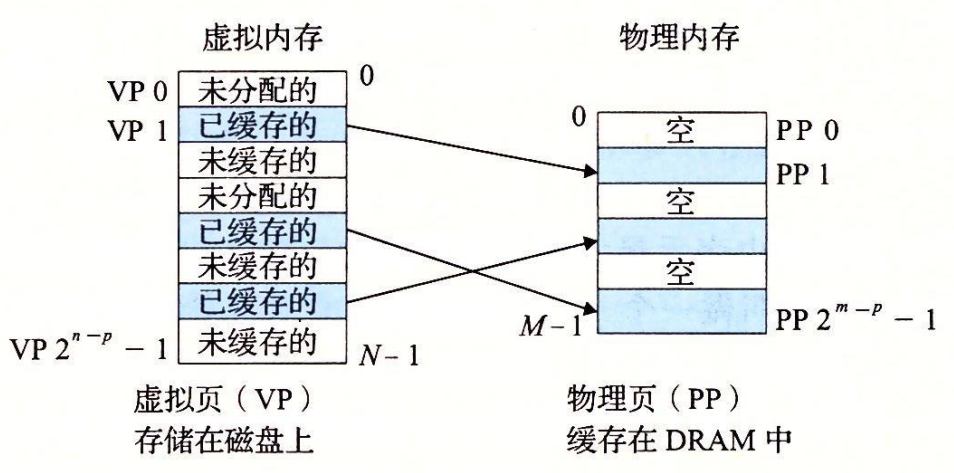
特点:按需页面调度
- 按需页面调度:如下图,只有实际驻留在物理内存空间中的页(已缓存的)才会对应着物理块。
- 如果不命中,系统必须判断这个虚拟页存放在磁盘的哪个位置,在物理内存中选择一个牺牲页,并将虚拟页从磁盘复制到 DRAM 中,替换这个牺牲页。
- 未缓存的:未缓存在物理内存中的已分配页,在磁盘上有对应位置。
- 未分配的:VM 系统还未分配(或者创建)的页。未分配的块没有任何数据和它们相关联,因此也就不占用任何磁盘空间。
 { width=80% }
{ width=80% }
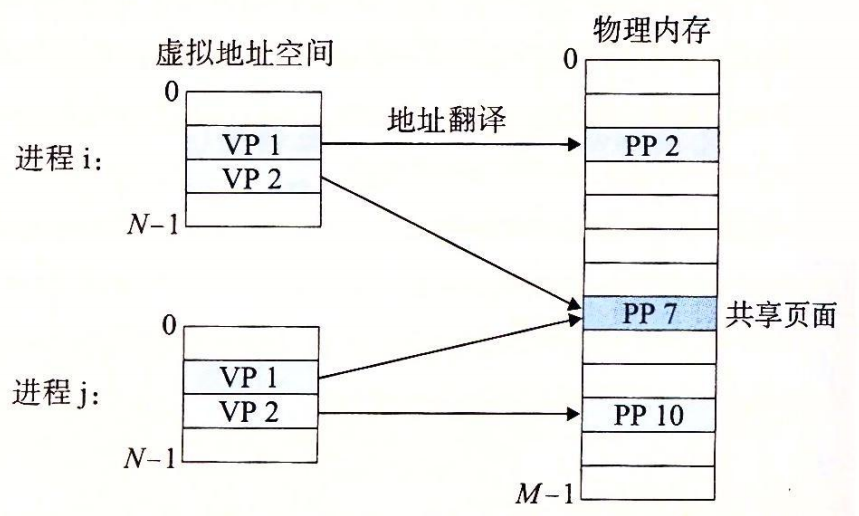
特点:进程的独立页表和独立虚拟地址空间
- 操作系统为每个进程提供了一个独立的页表,因而也就是一个独立的虚拟地址空间。
- 注意,多个虚拟页面可以映射到同一个共享物理页面上。
- 利用这点,多个程序可以使用同一个动态库文件(.so)文件。比如printf
 { width=80% }
{ width=80% }
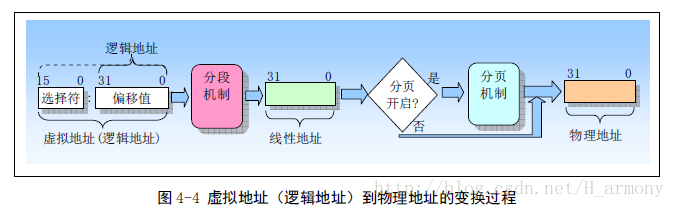
Linux内存分段分页机制
下图展示了虚拟地址进过分段、分页机制后转化成物理地址的简单过程。其实分段机制是intel芯片为兼容以前产品而保留下来的,然后linux中弱化了这一机制。下面我们先简单介绍一下分段机制:
 { width=80% }
{ width=80% }
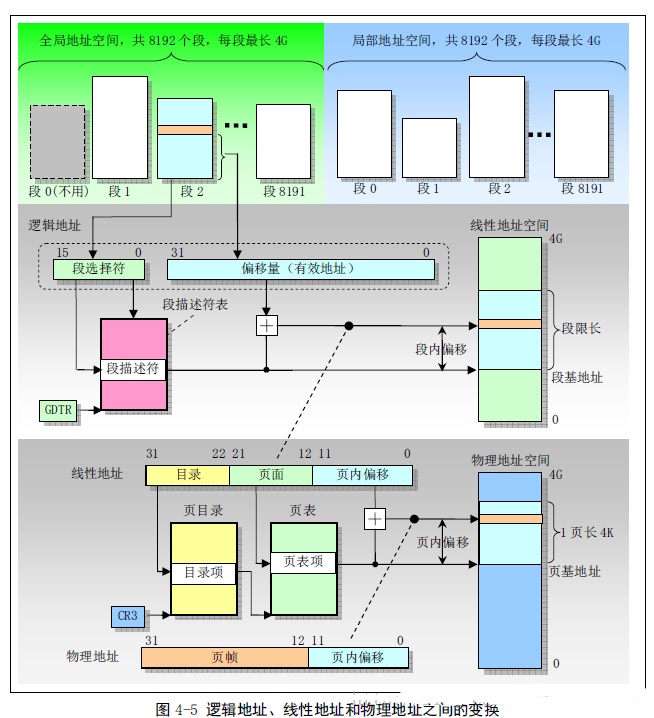
- 分段机制隔绝了各个代码、数据和堆栈区域,它把处理器可寻址的线性地址空间划分成一些较小的称为段的受保护地址空间区域。
- 每个逻辑段对应着一个自然的片段,如函数、数组等,每个逻辑段的长度可以根据需要动态地进行调整。每个逻辑段都有自己的段基址和段长度,当程序执行时,将它们映射到物理内存的若干个物理块中。
- 好处:方便了程序员对程序的管理和调试,同时还可以缓解内存碎片的问题,提高内存利用率。
- 分页机制会把线性地址空间(段已映射到其中)划分成页面,然后这些线性地址空间页面被映射到物理地址空间的页面上。
- 不同之处:分段机制主要针对程序的逻辑单元进行内存管理,而分页机制则是针对物理内存进行内存管理,把内存视为一个固定大小的块进行划分。
 { align=right }
{ align=right }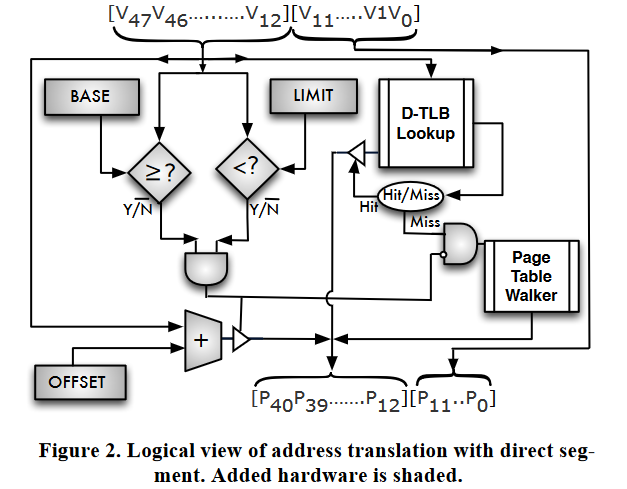
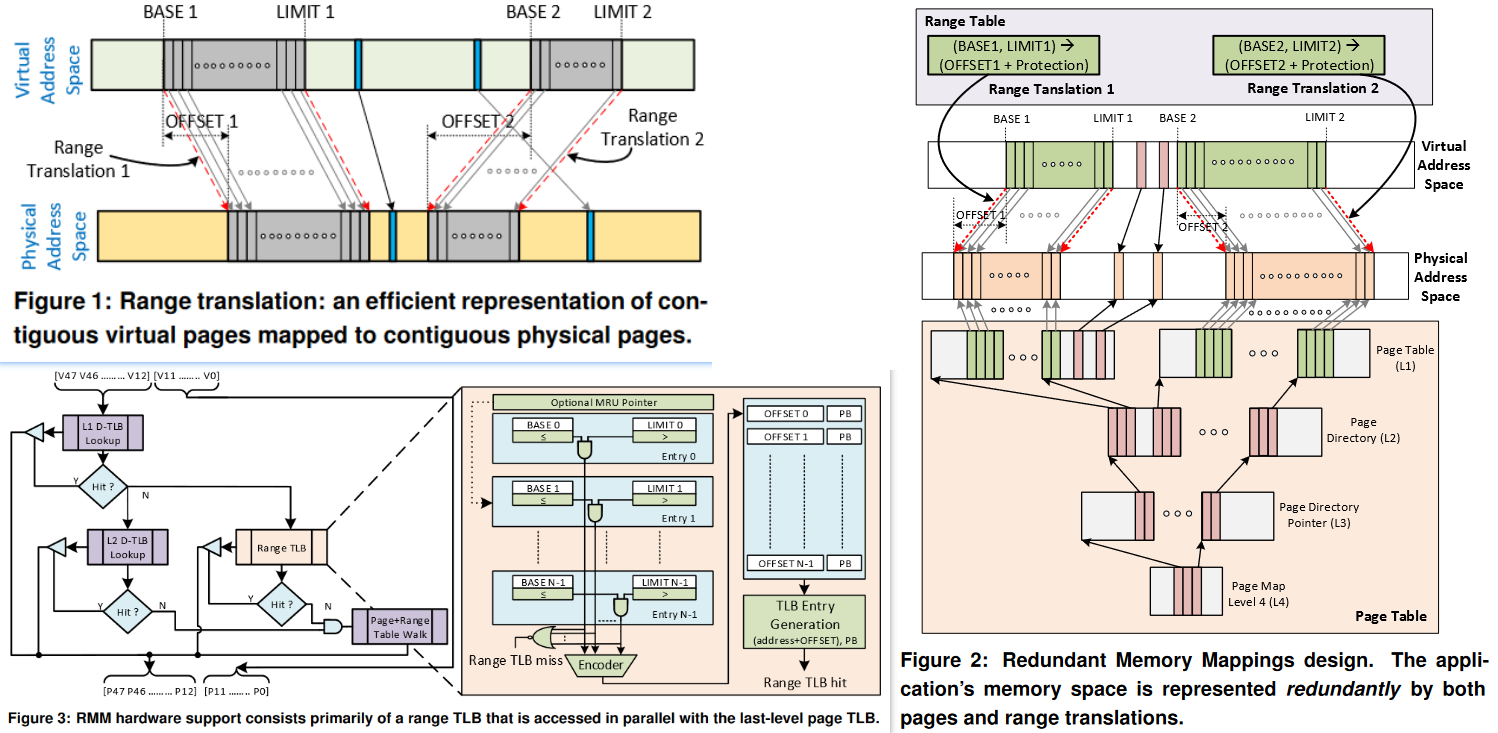 [^22]
[^22]如何使用页表:地址翻译
- Address translation: the process of determining the physical address from the virtual address
- 下图展示了 MMU 如何利用页表来实现这种映射。
- CPU 中的一个控制寄存器,页表基址寄存器(Page Table Base Register,PTBR)指向当前页表。
- n 位的虚拟地址包含两个部分:一个 p 位的虚拟页面偏移(Virtual Page Offset,VPO)和一个位的虚拟页号(Virtual Page Number,VPN)。
- MMU 利用 VPN 来选择适当的 PTE。例如,VPN 0 选择 PTE 0,VPN 1 选择 PTE 1,以此类推。将页表条目中物理页号(Physical Page Number,PPN)和虚拟地址中的 VP。串联起来,就得到相应的物理地址。
- 注意,因为物理和虚拟页面都是 P 字节的,所以物理页面偏移(Physical Page Offset,PPO)和 VPO 是相同的。
 { width=80% }
{ width=80% }
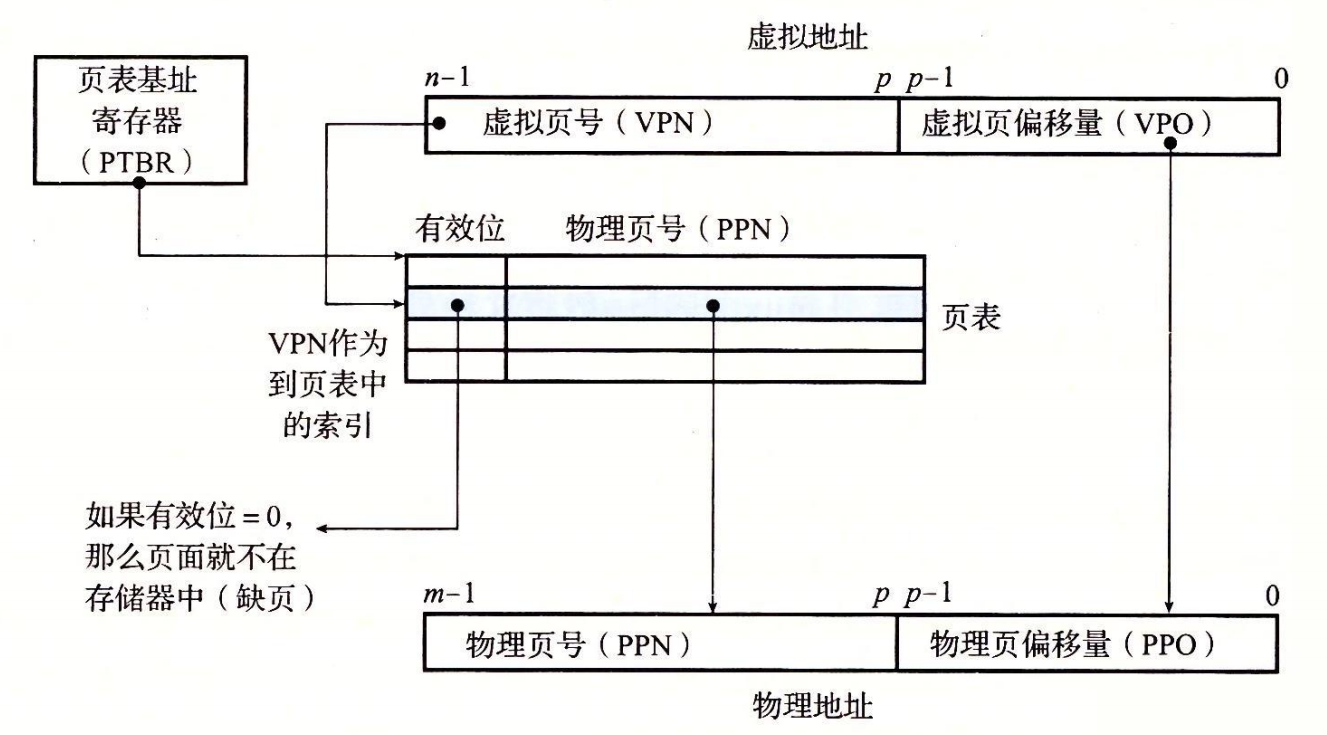
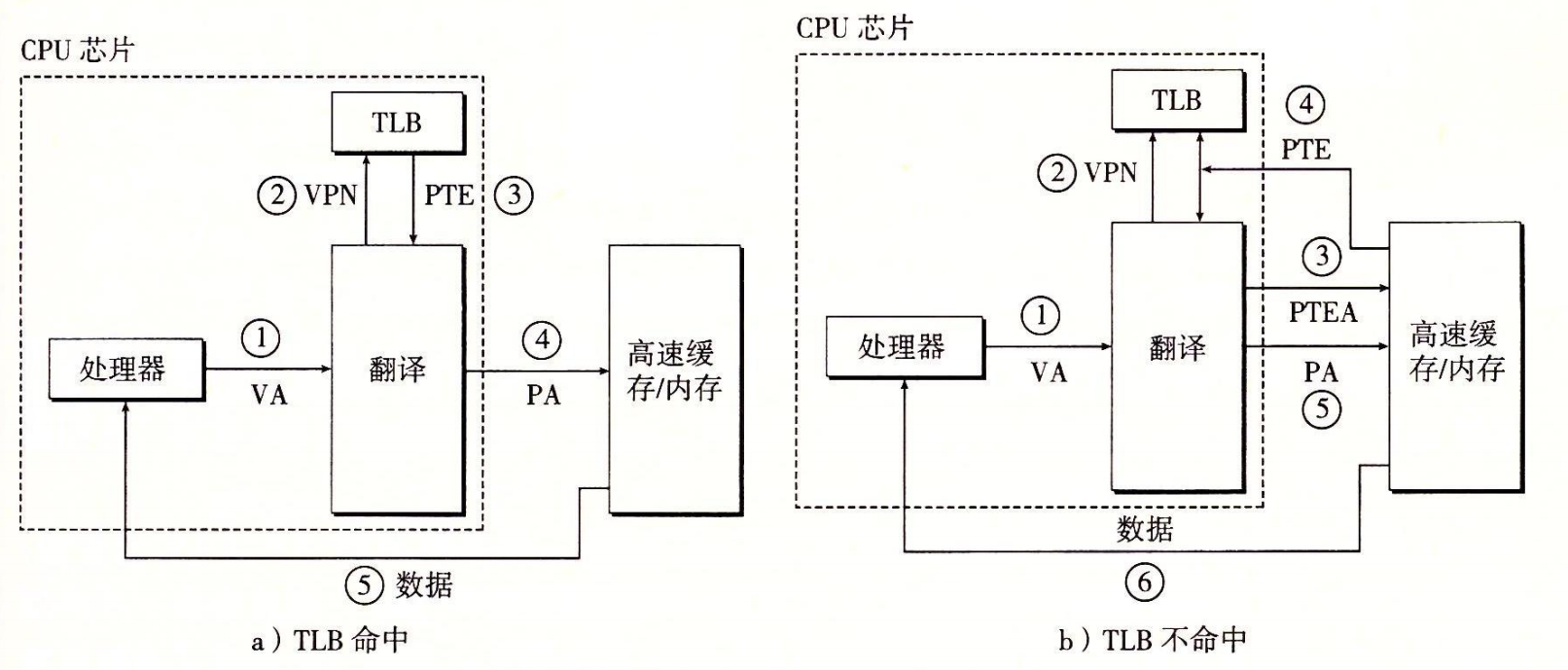
页面命中,硬件执行流程
- 第 1 步:处理器生成一个虚拟地址VA,并把它传送给 MMU。
- 第 2 步:MMU 生成 PTE 物理地址,并从高速缓存/主存请求得到它。(页表内容也能被缓存?)
- 第 3 步:高速缓存/主存向 MMU 返回 PTE。
- 第 4 步:MMU 构造物理地址,并把它传送给高速缓存/主存。
- 第 5 步:高速缓存/主存返回所请求的数据字给处理器。
缺页,硬件执行流程
页面命中完全是由硬件来处理的,与之不同的是,处理缺页要求硬件和操作系统内核协作完成,如下图所示。
- 第 1 步到第 3 步:相同。
- 第 4 步:PTE 中的有效位是零,所以 MMU 触发了一次异常,传递 CPU 中的控制到操作系统内核中的缺页异常处理程序。
- 第 5 步:缺页处理程序确定出物理内存中的牺牲页,如果这个页面已经被修改了,则把它换出到磁盘。
- 第 6 步:缺页处理程序页面调入新的页面,并更新内存中的 PTE。
- 第 7 步:缺页处理程序返回到原来的进程,再次执行导致缺页的指令。CPU 将引起缺页的虚拟地址重新发送给 MMU。因为虚拟页面现在缓存在物理内存中,所以就会命中。
 { width=80% }
{ width=80% }
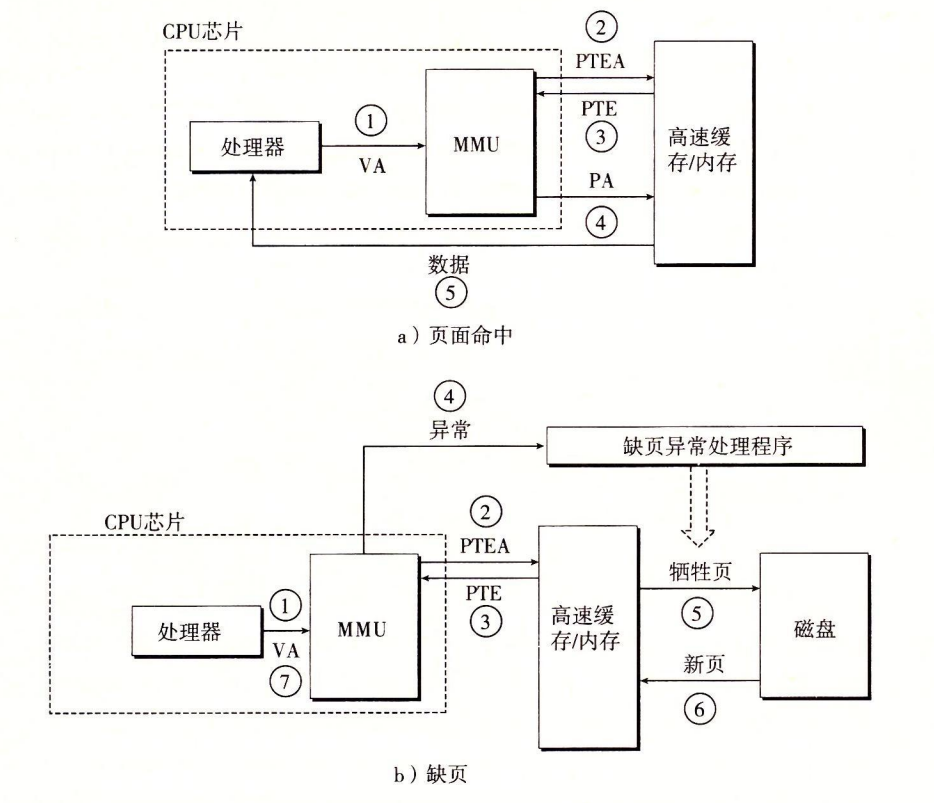
页表的存储、结合高速缓存和虚拟内存
- 大部分系统的cache是选择物理寻址的
- 页表是需要一直驻留在物理内存中的(多级页表除外)。注意,页表条目可以缓存,就像其他的数据字一样,因为地址翻译发生在高速缓存查找之前。如下图
 { width=80% }
{ width=80% }
利用 TLB 加速地址翻译
- 每次 CPU 产生一个虚拟地址,MMU 就必须查阅一个 PTE,以便将虚拟地址翻译为物理地址。
- 在最糟糕的情况下,这会要求从内存多取一次数据(多级页表更多次),代价是几十到几百个周期。
- 如果 PTE 碰巧缓存在 L1 中,那么开销就下降到 1 个或 2 个周期。
- 然而,许多系统都试图消除即使是这样的开销,它们在 MMU 中包括了一个关于 PTE 的小的缓存,称为翻译后备缓冲器(Translation Lookaside Buffer,TLB)。
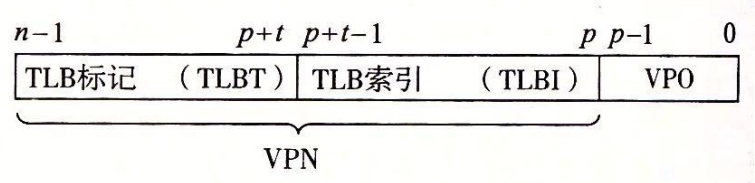
- TLB 是一个小的、虚拟寻址的缓存,其中每一行都保存着一个由单个 PTE 组成的块。TLB 通常有高度的相联度。
- 如图所示,用于组选择和行匹配的索引和标记字段是从虚拟地址中的虚拟页号中提取出来的。如果 TLB 有个组,那么 TLB 索引(TLBI)是由 VPN 的 t 个最低位组成的,而 TLB 标记(TLBT)是由 VPN 中剩余的位组成的。
 { width=80% }
{ width=80% }
- 如图所示,用于组选择和行匹配的索引和标记字段是从虚拟地址中的虚拟页号中提取出来的。如果 TLB 有个组,那么 TLB 索引(TLBI)是由 VPN 的 t 个最低位组成的,而 TLB 标记(TLBT)是由 VPN 中剩余的位组成的。
- 下图展示了当 TLB 命中时(通常情况)所包括的步骤。这里的关键点是,所有的地址翻译步骤都是在芯片上的 MMU 中执行的,因此非常快。
 { width=80% }
{ width=80% }
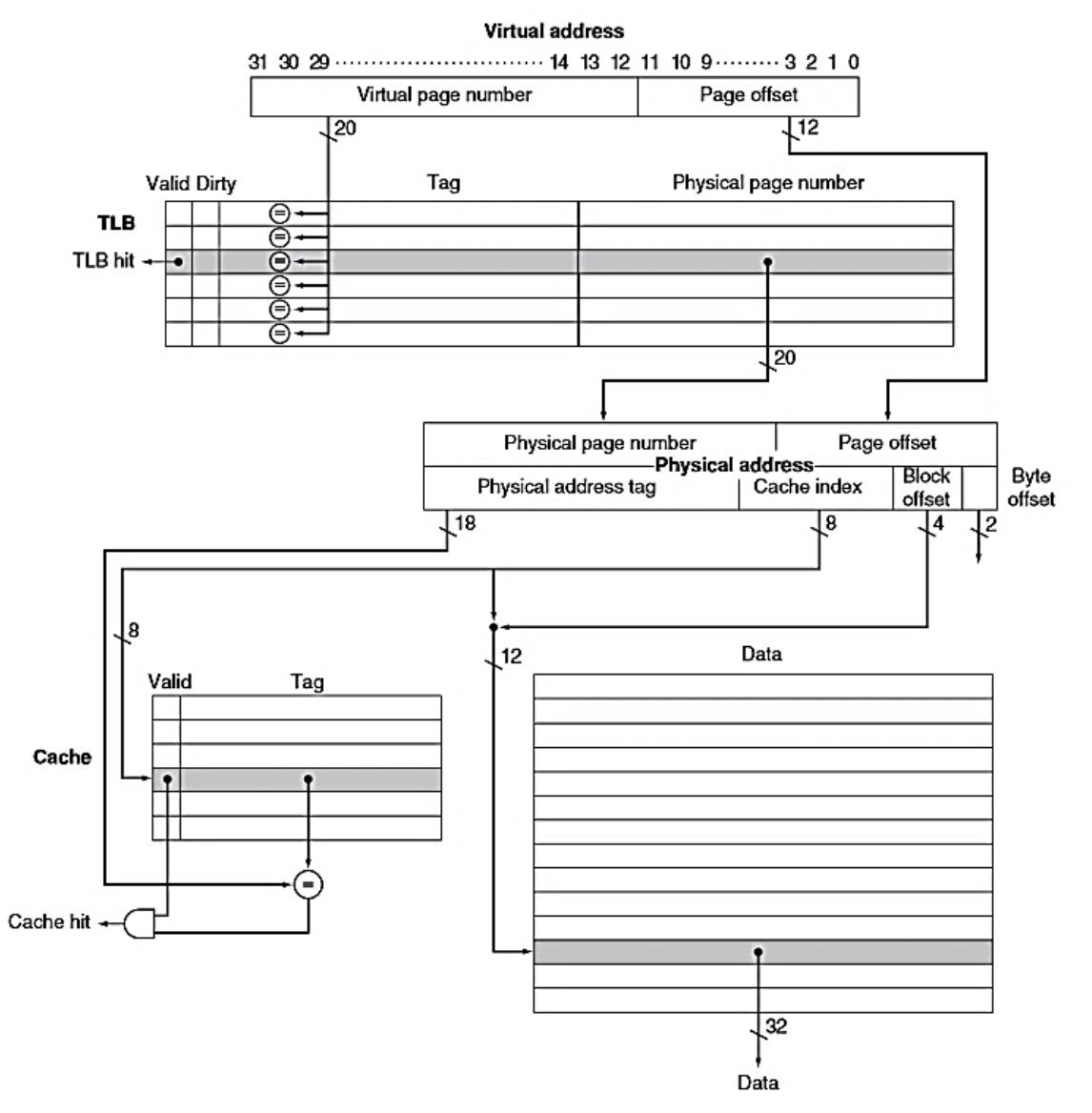
TLB Cache 的 VA PA 细节
 { width=80% }
{ width=80% }
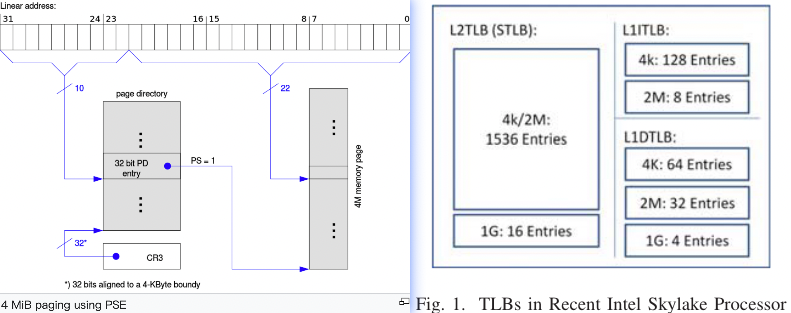
TLB support multi-size page
 { width=80% }
{ width=80% }
- Enabling Page Size Extension,PSE (by setting bit 4, PSE, of the system register CR4) changes this scheme.
- The entries in the page directory have an additional flag, in bit 7, named PS (for page size). This flag was ignored without PSE, but now, the page-directory entry with PS set to 1 does not point to a page table, but to a single large 4 MiB page. The page-directory entry with PS set to 0 behaves as without PSE.
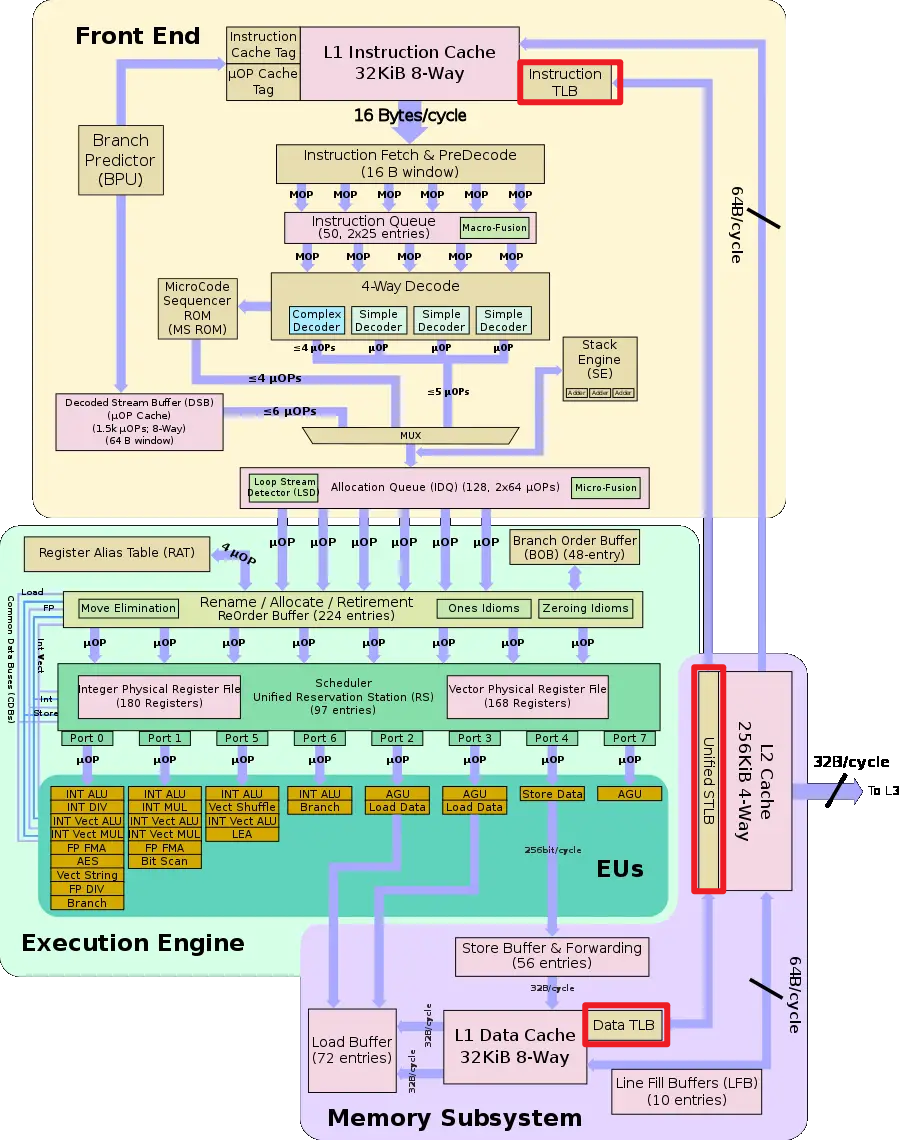
TLB的多级结构
TLB(Translation Lookaside Buffer)在物理结构上可以有多级结构,也可以只有单级结构,具体取决于处理器的架构和设计。 如Intel 的skylake就明显有两级TLB。
 { width=80% }
{ width=80% }
Attention: L1 Virtually Indexed Cache
Skylake架构中,DTLB位于L1数据缓存之后。这说明Skylake的L1数据缓存是虚拟地址索引的缓存(Virtually Indexed Cache), L2 就是物理地址。
在虚拟地址索引的缓存中,缓存的索引使用的是虚拟地址的一部分,而不是物理地址。主要有以下几点原因:
- 简化缓存访问,提高访问速度:可以直接拿到指令的虚拟地址进行索引,不需要等待地址翻译。避免了需要先查询TLB才能获取物理地址再索引的额外延迟。
- 缩小关键路径:允许并行进行缓存访问和地址翻译,缩短了关键路径延迟。
更高命中率:由于运行程序使用的都是虚拟地址,使用虚拟地址索引可以提供更高的时间局部性,提高缓存命中率。
简化一致性:由于L1缓存仅被一个core访问,使用虚拟地址索引可以简化缓存一致性协议。
但是,虚拟地址索引也存在一个问题,就是当地址映射关系变更时(比如,进程上下午切换),可能需要刷新或回写缓存行。总体来说,Skylake的设计选择了使用虚拟缓存来获得访问速度上的优势
小结
 { width=80% }
{ width=80% }
多级页表
缘由
- 到目前为止,我们一直假设系统只用一个单独的页表来进行地址翻译。
- 如果我们有一个 32 位的地址空间、4KB 的页面(4*1K = 12位的PPO,最多余下20位VPN = 1M,说明有1M个页表项)和一个 4 字节的 PTE,那么即使应用所引用的只是虚拟地址空间中很小的一部分,也总是需要一个 4MB 的页表驻留在内存中。对于地址空间为 64 位的系统来说,问题将变得更复杂。
- 用来压缩页表大小的常用方法是使用层次结构的页表。
多级页表构建实例
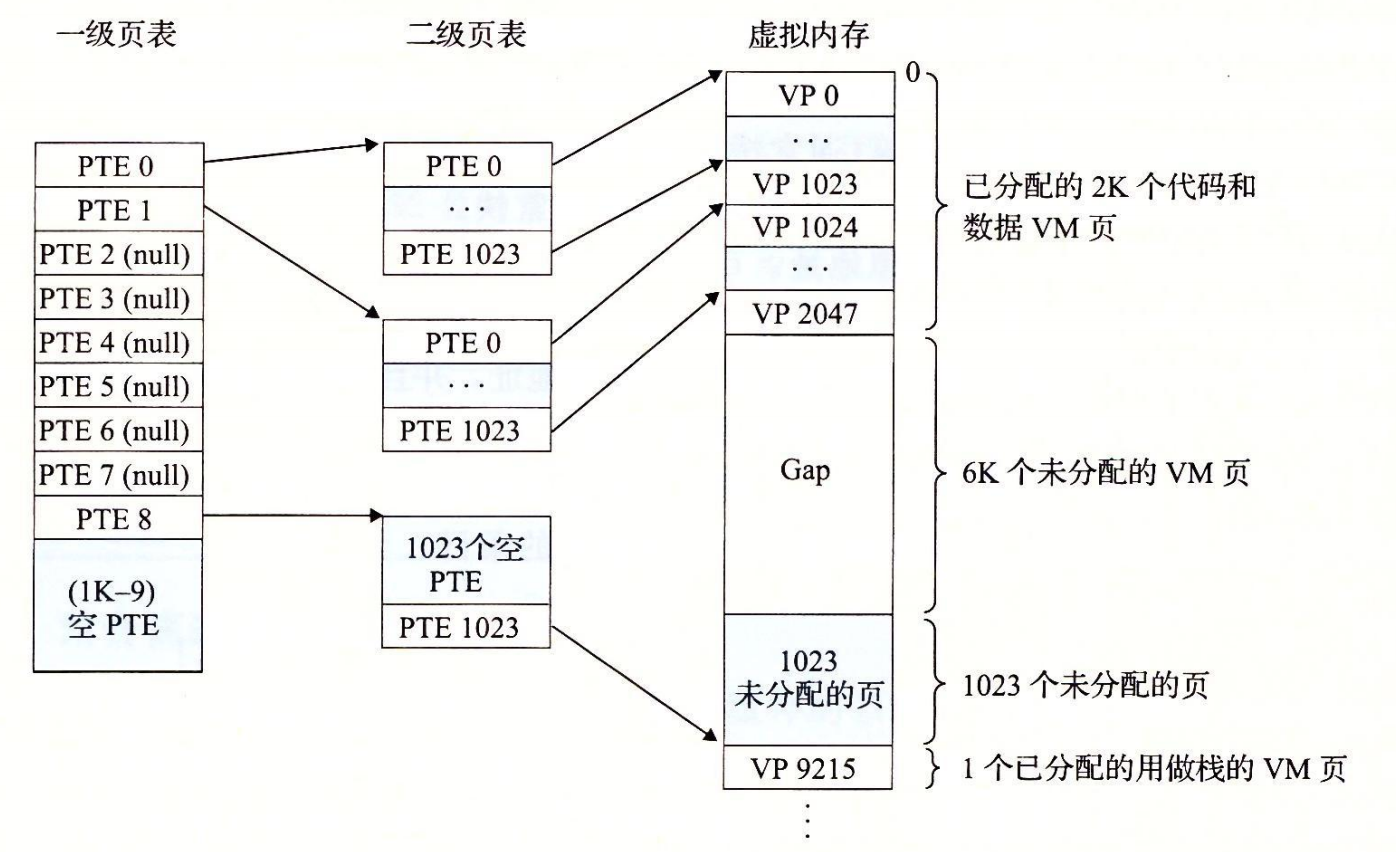
假设 32 位虚拟地址空间被分为 4KB 的页,而每个页表条目都是 4 字节。
还假设在这一时刻,虚拟地址空间有如下形式:内存的前 2K 个页面分配给了代码和数据,接下来的 6K 个页面还未分配,再接下来的 1023 个页面也未分配,接下来的 1 个页面分配给了用户栈。
下图 展示了我们如何为这个虚拟地址空间构造一个两级的页表层次结构。
 { width=80% }
{ width=80% }一级页表中的每个 PTE 负责映射虚拟地址空间中一个 4MB 的片(chunk),负责1个二级页表。二级页表中的每个 PTE 都负责映射一个 4KB 的虚拟内存页面。
每个一级和二级页表都是 4KB 字节,这刚好和一个页面的大小是一样的。
优点:
- 第一,如果一级页表中的一个 PTE 是空的,那么相应的二级页表就根本不会存在。对于一个典型的程序,4GB 的虚拟地址空间的大部分都会是未分配的。
- 第二,只有一级页表才需要总是在主存中,这就减少了主存的压力;只有最经常使用的二级页表才需要缓存在主存中。
多级页表地址翻译
 { width=80% }
{ width=80% } { width=80% }
{ width=80% }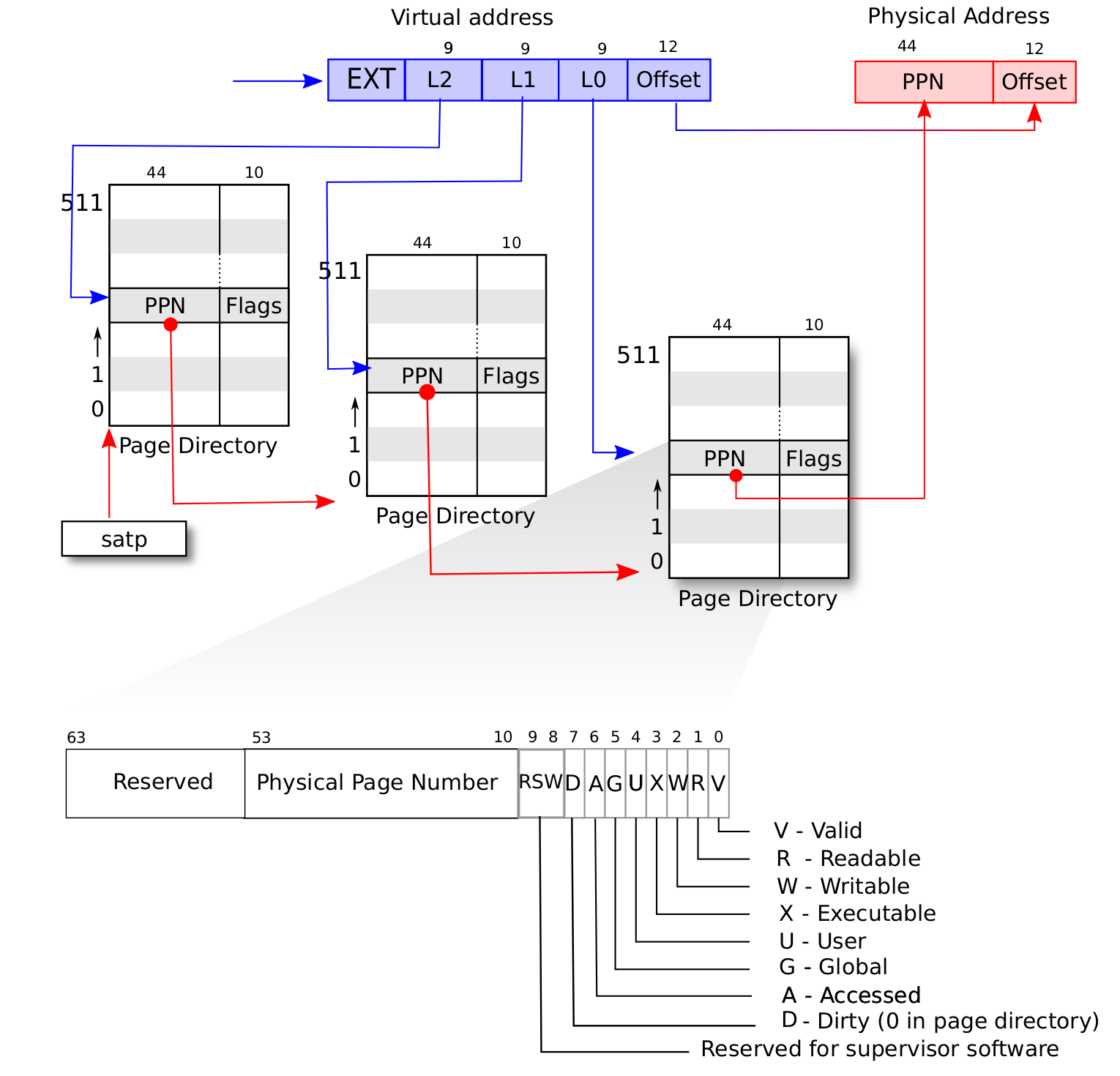 { width=80% }
{ width=80% }
Core i7 实例
层次结构TLB 是虚拟寻址的,是四路组相联的。L1、L2 和 L3 高速缓存是物理寻址的,块大小为 64 字节。
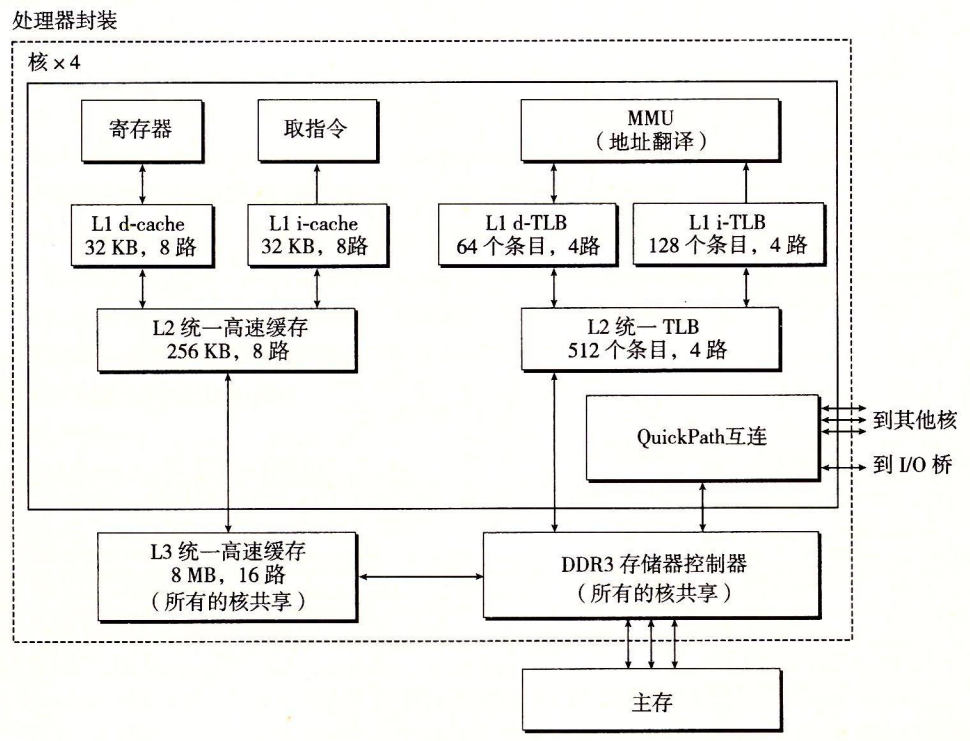 { width=80% }
{ width=80% }
CR3 控制寄存器指向第一级页表(L1)的起始位置。CR3 的值是每个进程上下文的一部分,每次上下文切换时,CR3 的值都会被恢复。
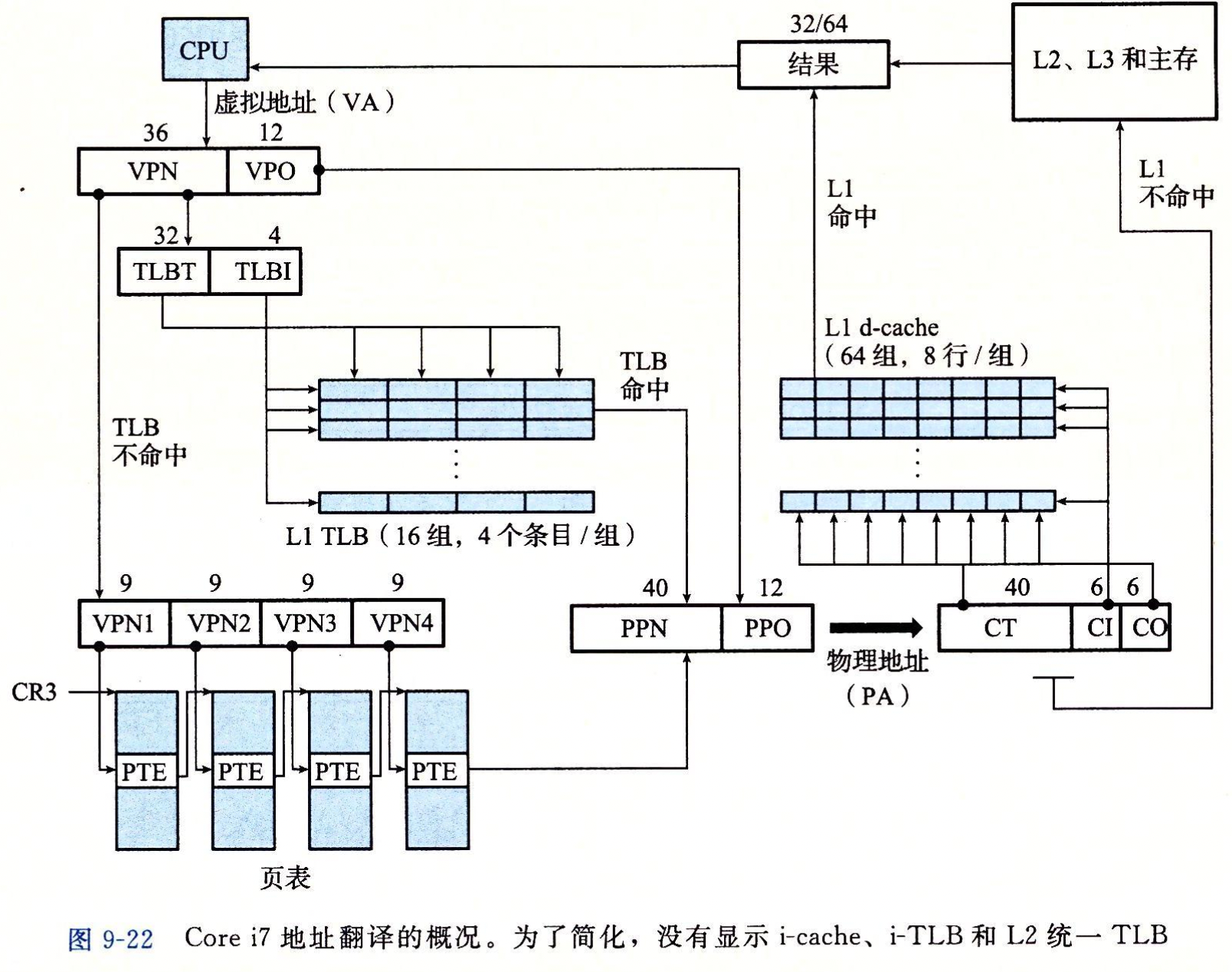 { width=80% }
{ width=80% }
Page Table Space Requirements
- In a 64-bit machine, each Page Table Entry (PTE) is 64 bits, which is equivalent to 8 bytes.
- With a 4-level page table structure, each level consists of $2^9 = 512$ entries, and therefore requires $512 * 8$ bytes, which equals 4KB.
Papers’ Motivations
Experiment Object
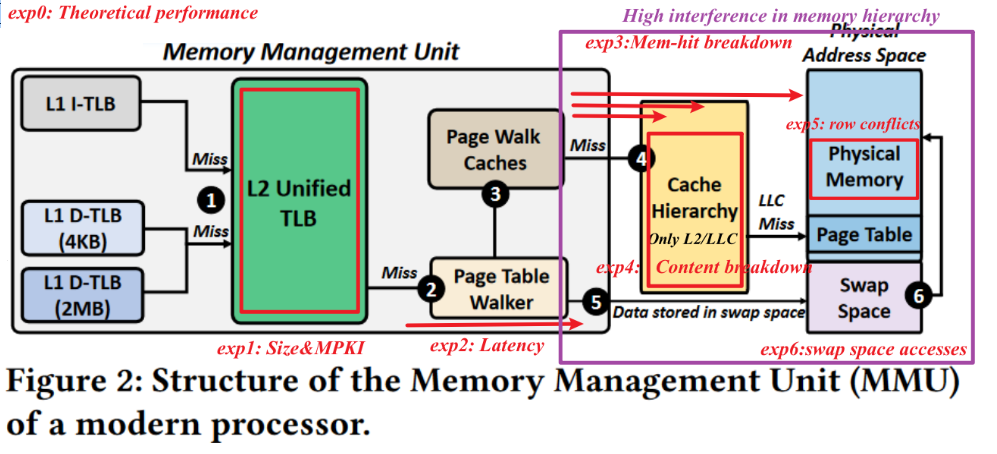
contiguous VM regions directly to contiguous VM.
- TLB and PWC can not cover the huger DRAM range.
- contiguous virtual memory regions directly to contiguous physical memory. -> More direct-map design[^28][^22]
TLB related
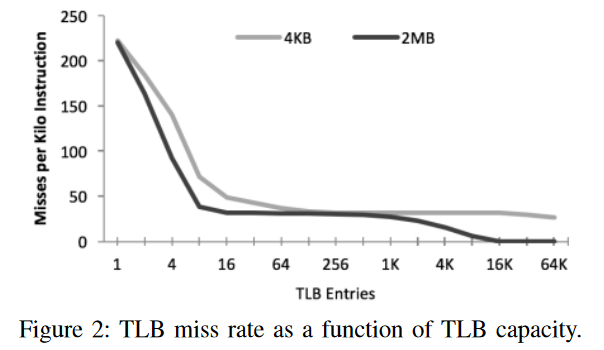 { width=80% }
{ width=80% }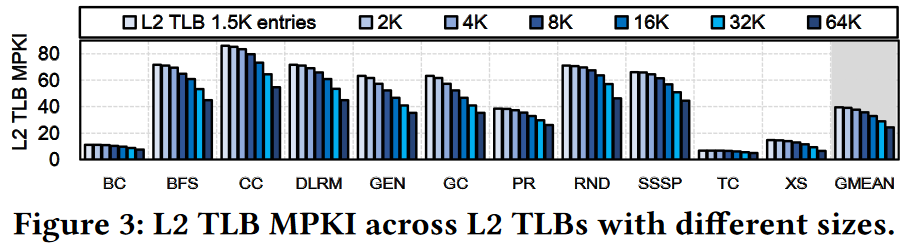
!!! example annotate “ideal system with perfect TLB”
Figure 6 shows the execution time speedup of ECH and P-TLB(1) compared to Radix. [^1]
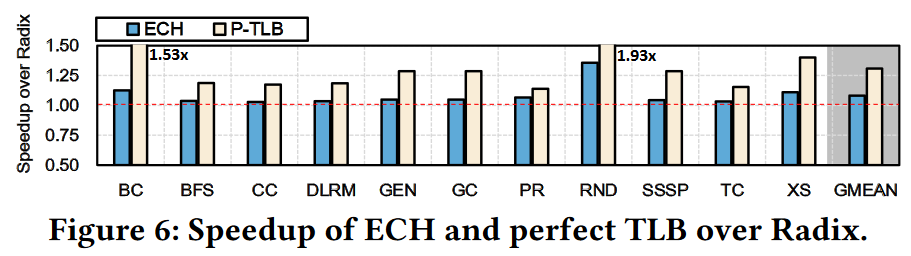
We observe that P-TLB outperforms Radix by 30% and ECH by 22%.
We conclude that there is room for further improving the performance of address translation.
- Every translation request hits in the L1 TLB.
High performance overheads
!!! quote annotate “Page Walk is costly: 1 TLB miss cause 4 references”
Radix page tables as implemented in the x86-64 architecture
incur a penalty of four memory references for address translation upon each TLB miss. These 4 references become 24 in
virtualized setups(1), accounting for 5%–90% of the runtime[^2]
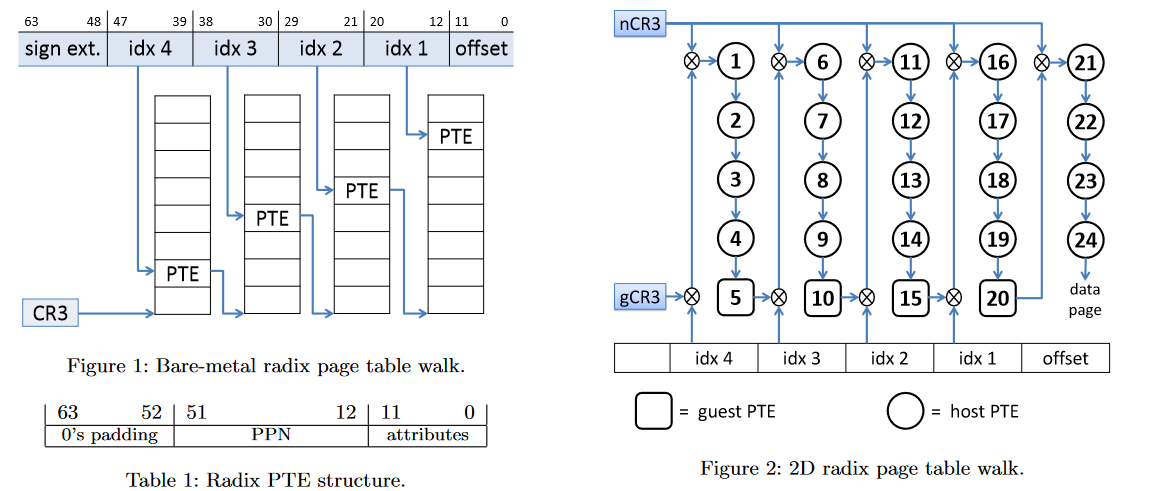{ width=80% }[^2]
- Hardware-assisted virtualization utilizes two layers of page tables, one for the host system and one for the guest virtual machine. The translation process of simultaneously walking these page tables is done in a “two-dimensional” (2D) manner, requiring 24 instead of 4 memory references.
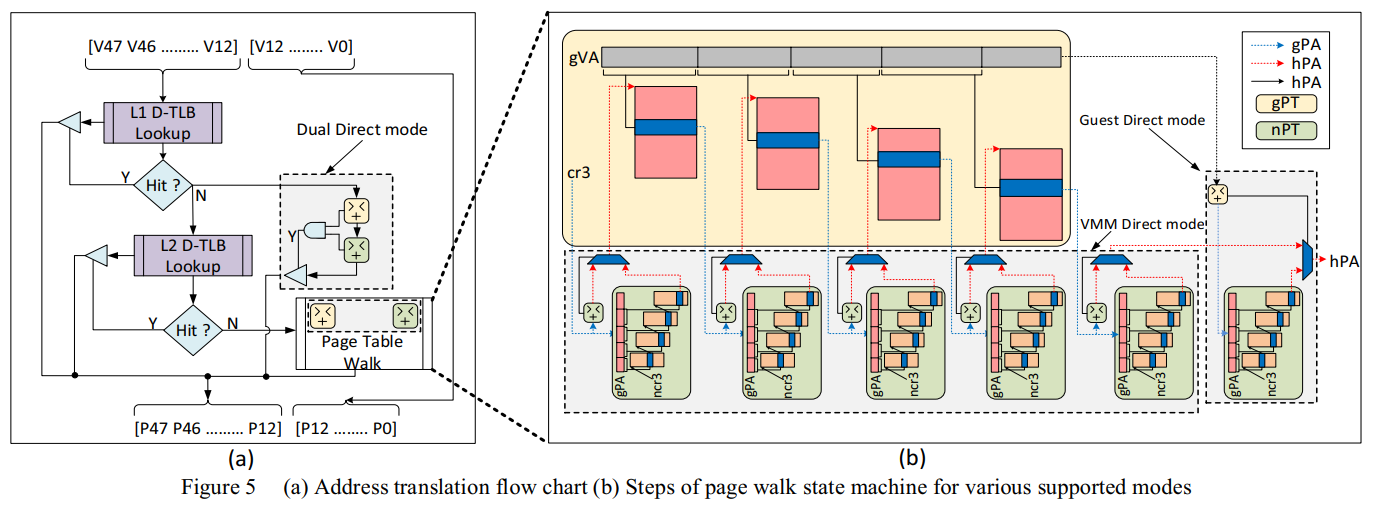 [^24]
[^24]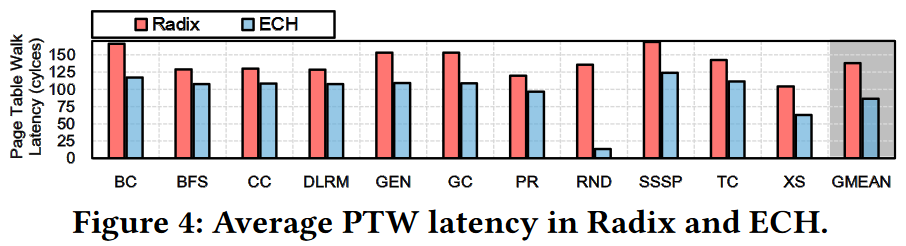
radix page table lack parallelism
its sequential pointer-chasing operation misses an opportunity: it does not exploit the ample memory-level parallelism that current computing systems can support.[^3]
High interference in memory hierarchy
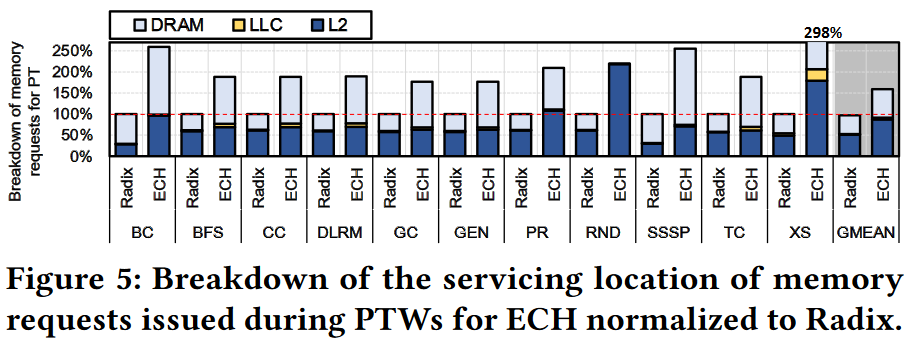
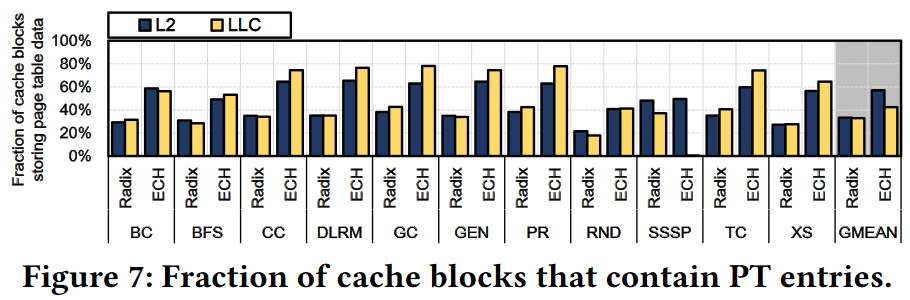
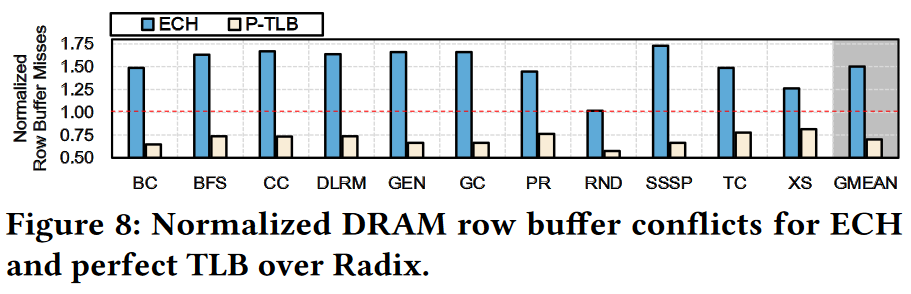
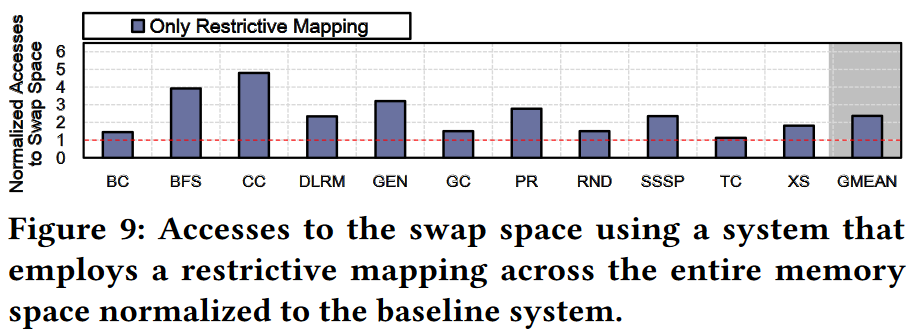
Solution to reduce V2P overhead
superpage
??? question annotate “how superpage get work”
To increase the reach of the TLB, the x86-64 architecture
supports two large page sizes, 2MB and 1GB. When a large
page is used, the page table walk is shortened. Specifically, a
2MB page translation is obtained from the PMD table(1), while
a 1GB page translation is obtained from the PUD table.[^3]
The **advantage** of super pages is that
1. a single TLB entry will be mapping a much larger amount(2) of virtual memory in turn reducing the number of **TLB misses**.
2. They also make the **page table walk slightly faster** on a TLB miss.[^5]
3. Reduce probability of page fault(3) when the first time the memory is accessed.[^9]
The **disadvantage** of super pages is that a process might not need all of that memory and so memory can be wasted.[^5] And requiring larger clear-page copy-page in page faults.[^9]
And superpage will keep the lower bits of page frame address reserved in PTE[^6][^7]
- PMD point to the 2MB page location (aligned in 2MB?) + lower bits offset => physical address
- by a factor of 512 for megapages, and 262144 for gigapages
- so reducing the enter/exit kernel frequency by a 512 or 262144 times factor
PWC
??? note annotate “Page Walk Caches (PWCs)”
PSCs (four in number for a five-level page table) store the recently accessed PTEs of intermediate page table levels. PTW searches all the PSCs concurrently after an STLB miss. In case of more than one hit, the farthest level is considered as it minimizes the page table walk latency.[^12]
To alleviate the overhead of page table walks, the MMU
of an x86-64 processor has small caches called Page Walk
Caches (PWCs)(1). The PWCs store recently-accessed PGD,
PUD, and PMD table entries (but not PTE entries). [^3]
On a TLB miss, before the hardware issues any request
to the cache hierarchy, it checks the PWCs. It records the
lowest level table at which it hits. Then, it generates an access
to the cache hierarchy for the next lower level table.
- named as PSC in Intel SDM 4.10.3 Paging-Structure Caches
Hashed-based instead of radix tree
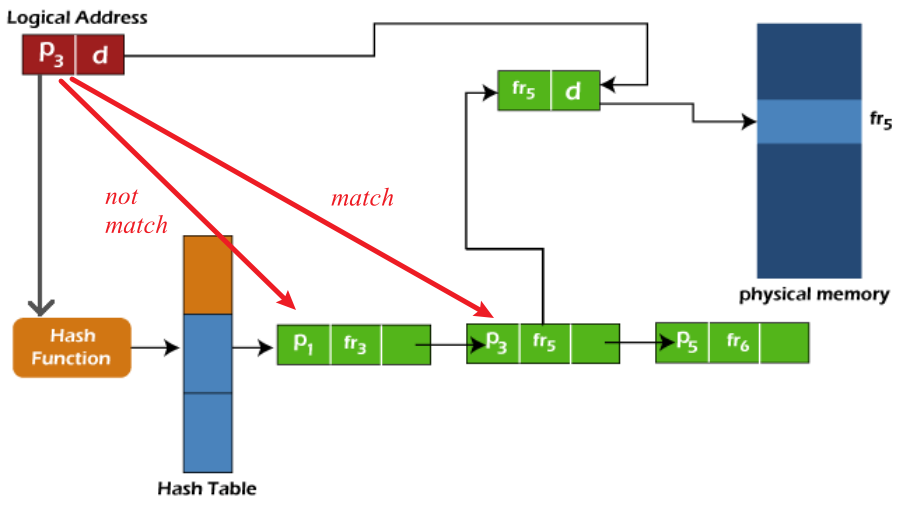 { width=80%}^13
{ width=80%}^13
- To solve hash collisions, the each entry in the hash table has a link list/collision chaining or open addressing basic machanisim or newer [^2].
- Advantage: Assuming that there is no hash collision, only one memory system access is needed for address translation.
- Challenges but solved in paper: [^3]
1. the loss of spatial locality in the accesses to the page table. This is caused by hashing, which scatters the page table entries of contiguous virtual pages.
2. the need to associate a hash tag (e.g., the virtual page number) with each page table entry, which causes page table entries to consume more memory space.
3. the need to handle hash collisions, which leads to more memory accesses, as the system walks collision chains
??? info annotate “Research 2016: “Page Table Entry Clustering & Compaction”
Yaniv and Tsafrir [^2] recently show that the first two limitations are addressable by careful design of page table entries. Specifically, they use **Page Table Entry Clustering**, where multiple contiguous page table entries are placed together in a single hash table entry that has a size equal to a cache line.
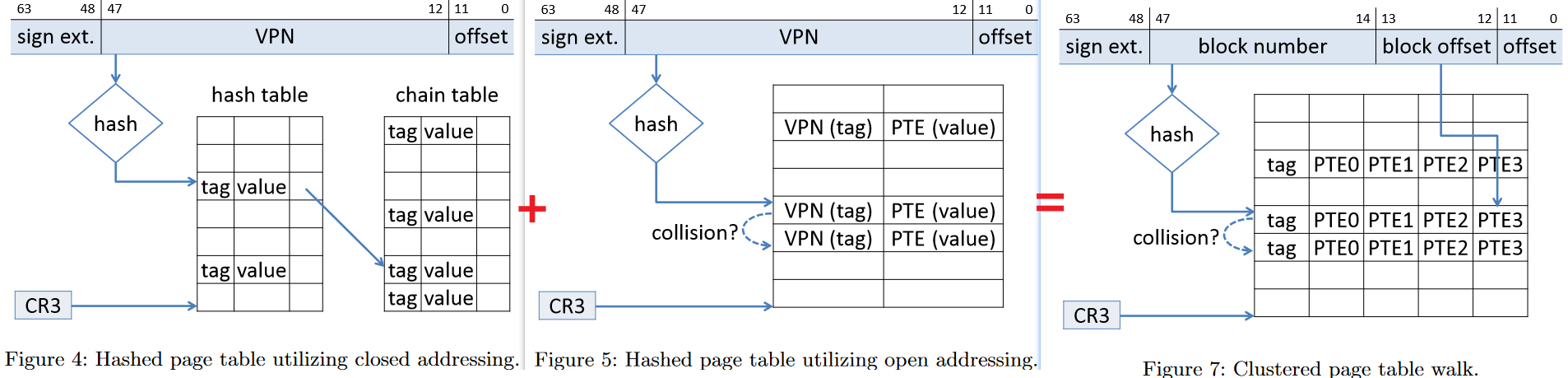
Further, they propose **Page Table Entry Compaction**(1), where unused upper bits of multiple contiguous page table entries are re-purposed to store the hash tag.
{ width=50% }
- We propose a new technique that further improves hashed page tables by compacting eight adjacent PTEs in a single 64-byte cache line, resulting in the spatial locality of hashed page tables similar to that of the x86-64 radix page tables. The clustered page tables, as were previously defined, cannot pack eight PTEs and a tag in a single cache line, since PTEs are 8 bytes long. But we can exploit the unused topmost bits of each PTE and store the tag in this unused space.
!!! question annotate “Why not use Single Global Hash Table”
A single global hash table that includes page table entries from all the active processes[^3]
- **Advantage**: 1) the hash table is allocated only once, and 2) the table can be sized(1)
- **drawback**
* neither **multiple page sizes** (e.g., huge pages) nor **page sharing** between processes can be supported without additional complexity.
* when a process is killed, the system needs to perform a linear scan of the entire hash table to find and **delete** the associated page table entries. Note that deleting an entry may also be costly
- to minimize the need for dynamic table resizing, which is very time consuming.
??? example annotate “Motivation: high hash collision probability”
Figure 2 shows the probability of random numbers mapping to the same hash table entry.(1)[^3]
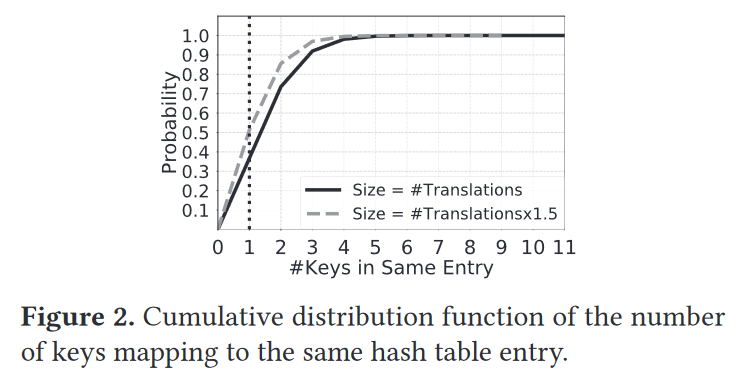
For the baseline table, we see that only 35% of the entries in the hash table have no collision (i.e, the number of colliding entries is 1). Even for the over-provisioned table(*1.5), only half of the entries in the table have no collision.
- We evaluate the following scenario: (1) the table has as many entries as the sum of all the translations required by all the applications, and (2) the hash function is the computationallyexpensive BLAKE cryptographic function [5] which minimizes the probability of collisions.
!!! note annotate “Elastic Cuckoo Hashing”
Elastic cuckoo hashing is a novel algorithm for cost-effective **gradual resizing** of **d-ary cuckoo hash tables**.
**Key idea 1**: target moved region
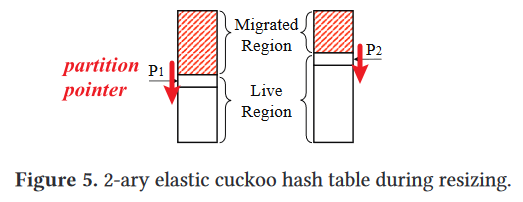
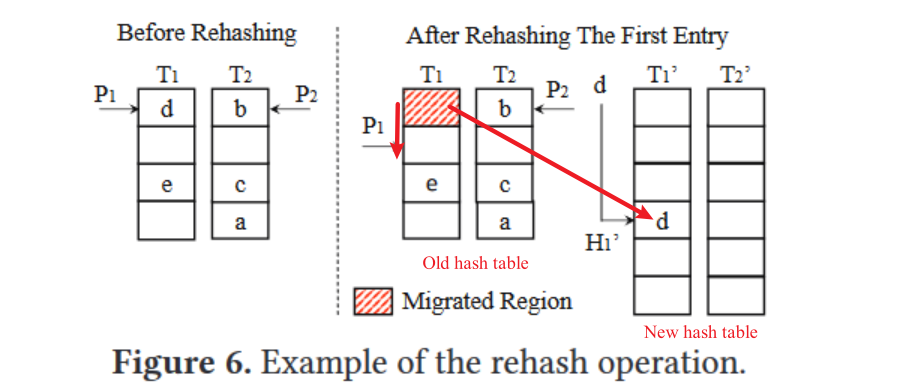
Operations: Rehash
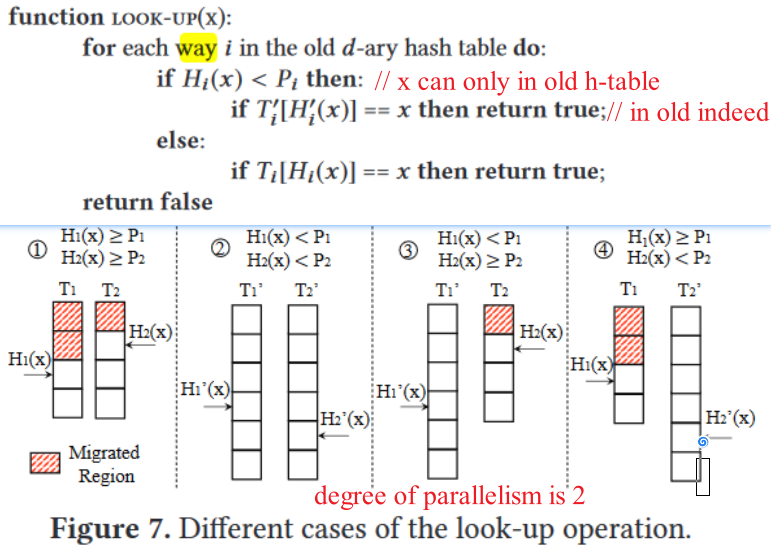
Operations: Lookup(parallisim)
Operations: insert(1)

**Key idea 2**: resize threshold is just like the machanism in vector space allocation, `k` times bigger
- We use
x ↔ yto denote the swapping of the values x and y, and use⊥to denote an empty value.
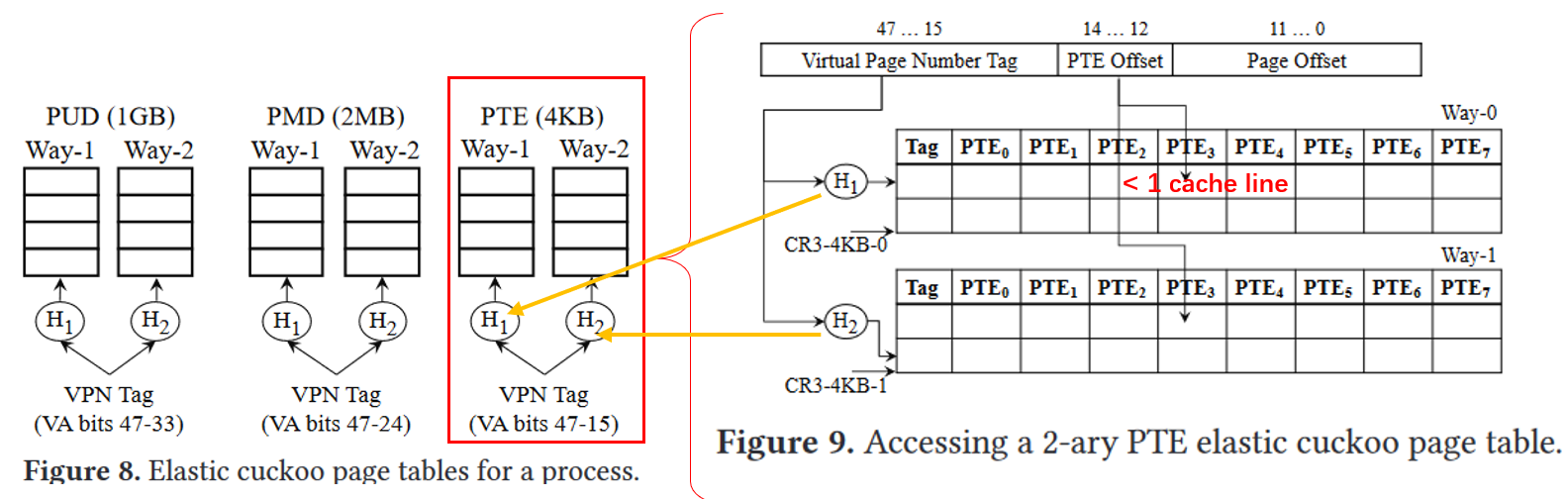
Clustered Page Table
The clustered page tables are similar to hashed page tables except that each entry in the hash table refers to many pages rather than one single page (as in a hashed page table). Hence, a single entry of a clustered page table can store the mappings for multiple physical page frames. ^13
Clustered page tables are useful for sparse address spaces, where memory references are scattered throughout the address space (non-contiguous).
Inverted Page Table
??? example annotate “How IPT get work”
The logical address consists of three entries `process id(1)/ ASID(2)`, `page number`, and the `offset`.
The match of `process id` and associated `page number` is searched in the page table and says if the search is found at the `ith` entry of page table, then `i and offset` together generate the physical address for the requested page. **The number i is the physical page number**.
- An inverted page table contains the address space information of all the processes in execution. Since two different processes can have a similar set of virtual addresses, it becomes necessary to store each process’s process ID to identify its address space uniquely in the Inverted Page Table.
- 12 bits address-space identifier (ASID) identifies the process currently active on the CPU. This is used to extend the virtual address when accessing the TLB.
??? example annotate “hashed IPT performence”
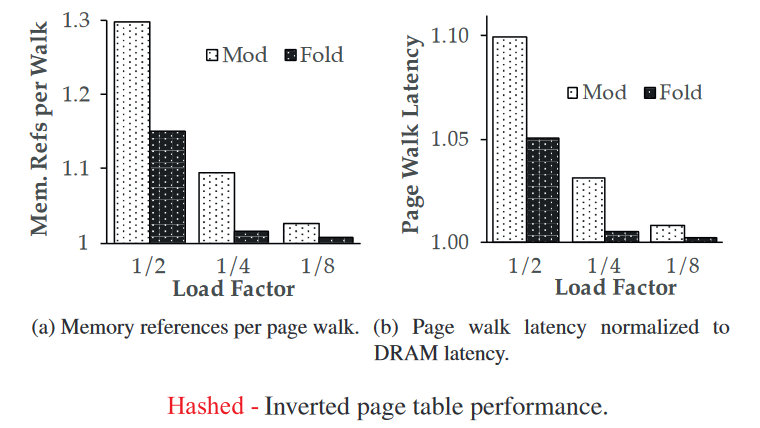
The rate of hash table collisions(1) is mainly determined by the ratio of occupied slots to the total number of slots, also called the **load factor**[^2]
**Mod**:conventional modulo hash [^14]
**Fold**:a stronger k-bit XOR folding
So we allocate **four times** of PTE for each 4KB page, due to the 1/4 load factor,
- open addressing for resolving conflicts, access the next one exploiting the locality in the DRAM row buffer.
??? question annotate “Why named Inverted”
1. Indexing using the frame number(1) instead of the logical page number(2).(why named Inverted)
2. Refer to translation metadata size, IPT is proportional to physical memory size. But conventional radix PT is proportional to `virtual address * process number`.
- the
ithentry is correspond to theithphysical page in memory space - the
ithentry is correspond to theithmalloced virtual page ???
??? note annotate “PACT’17: DIPTA (Distributed Inverted Page Table)”
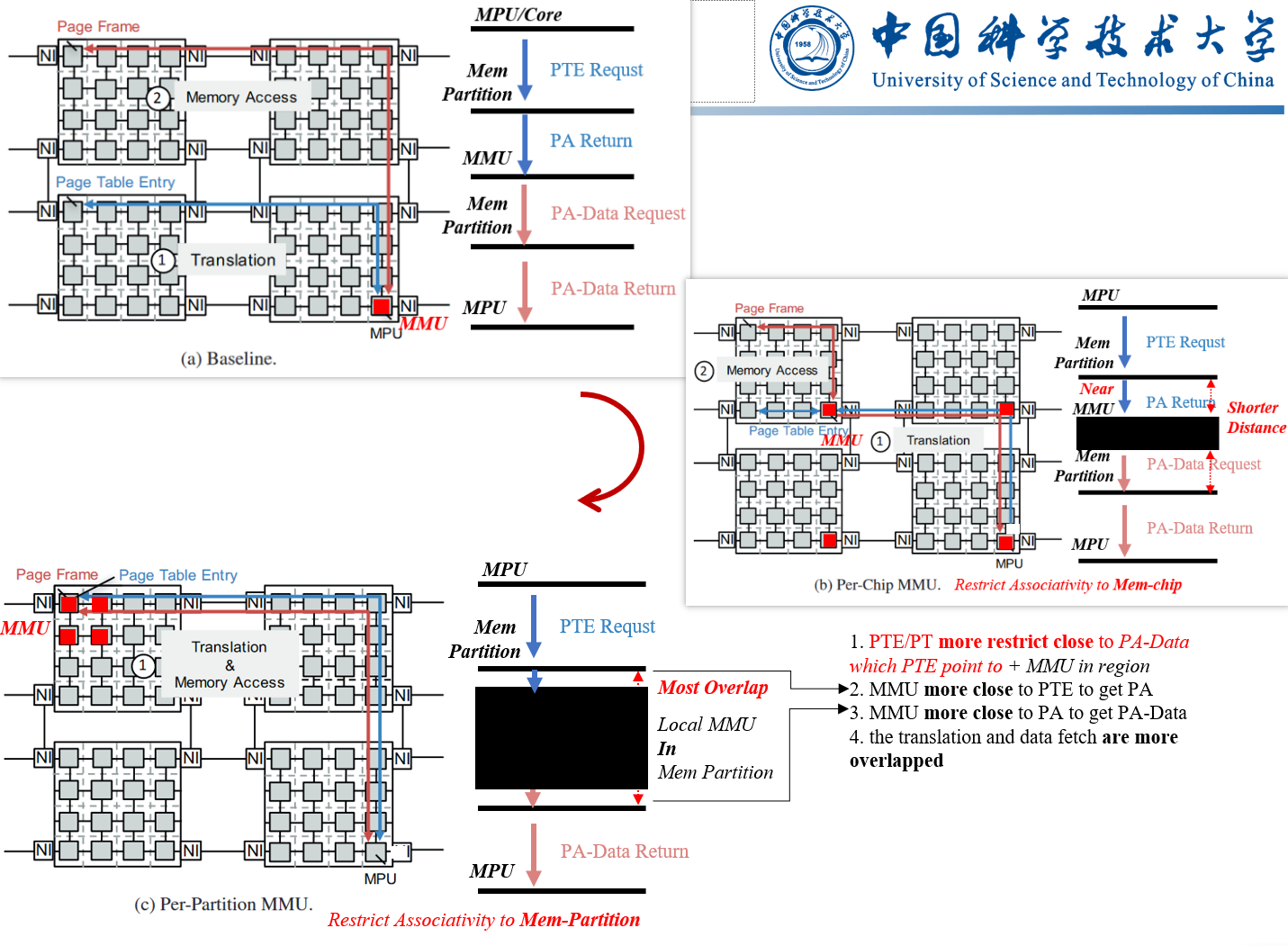
DIPTA restricts the associativity so that a page can only reside in a few number of physical locations which are physically adjacent–i.e., in the same memory chip and DRAM row.[^14]
**Ideas**:
1. Put metedata/MMU/data closer, the translation and data fetch time more be overlapped.
2. Restrict metadata closer to data, the MMU can be positioned deeper, the time more be saved.
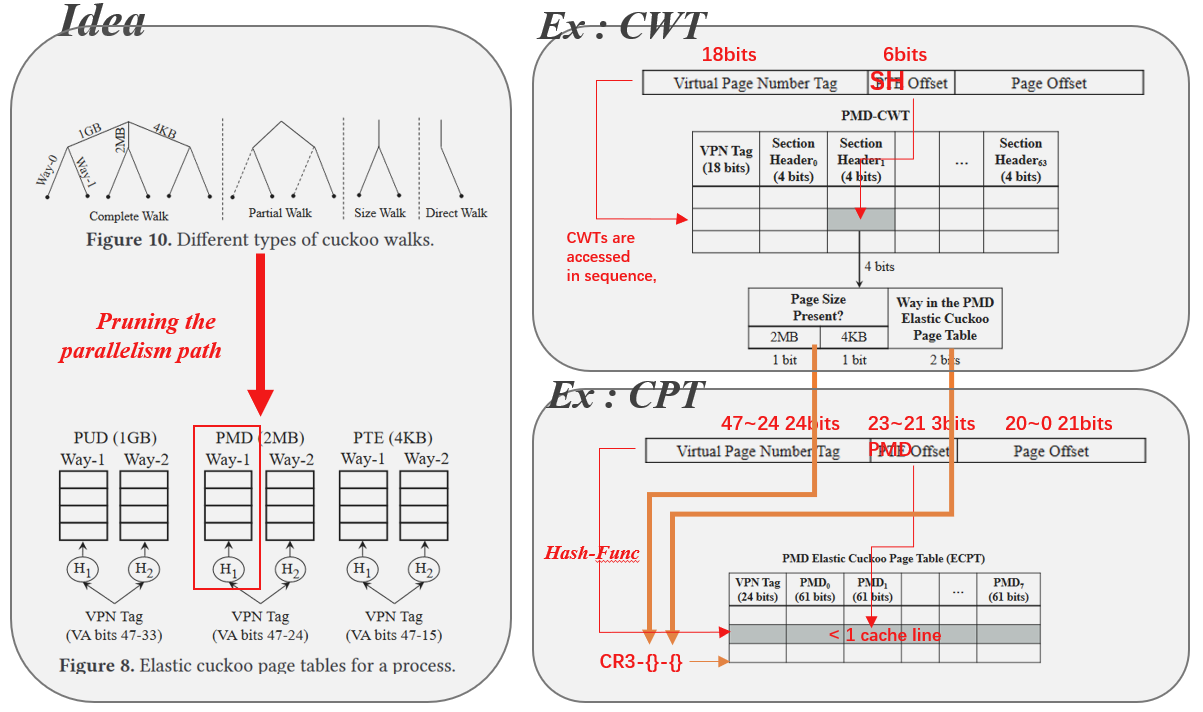
1. 
3. Leveraging Cache Structure for Efficiency: Cache-like designs leverage the benifit of restricting address translation. Two key techniques help make caches fast and efficient:
1. **Grouping** `n-ways` metadata together into `sets`
2. **Direct-mapping** between sets - From the perspective of an individual set, the cache acts as direct-mapped storage, meaning there is a **predictable** mapping between a memory address and which entry within the set will store it. This **eliminates complex logic** to search the entire cache, streamlining the placement and lookup process.
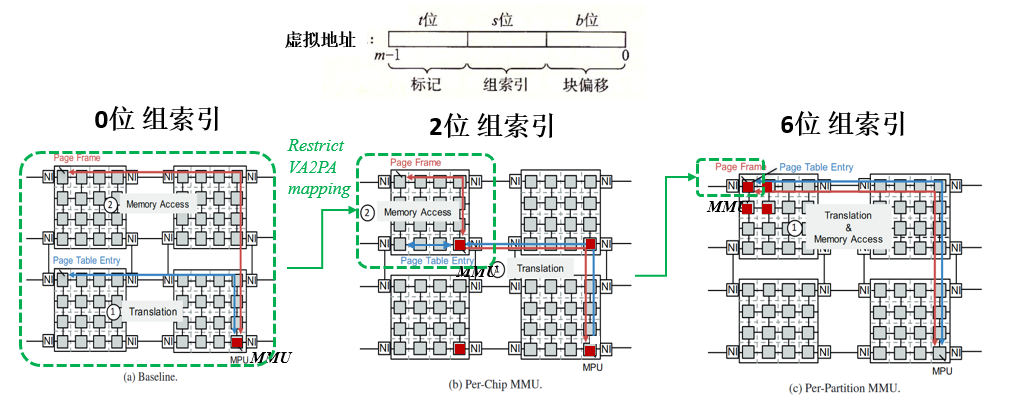
**Overview **
4. General idea 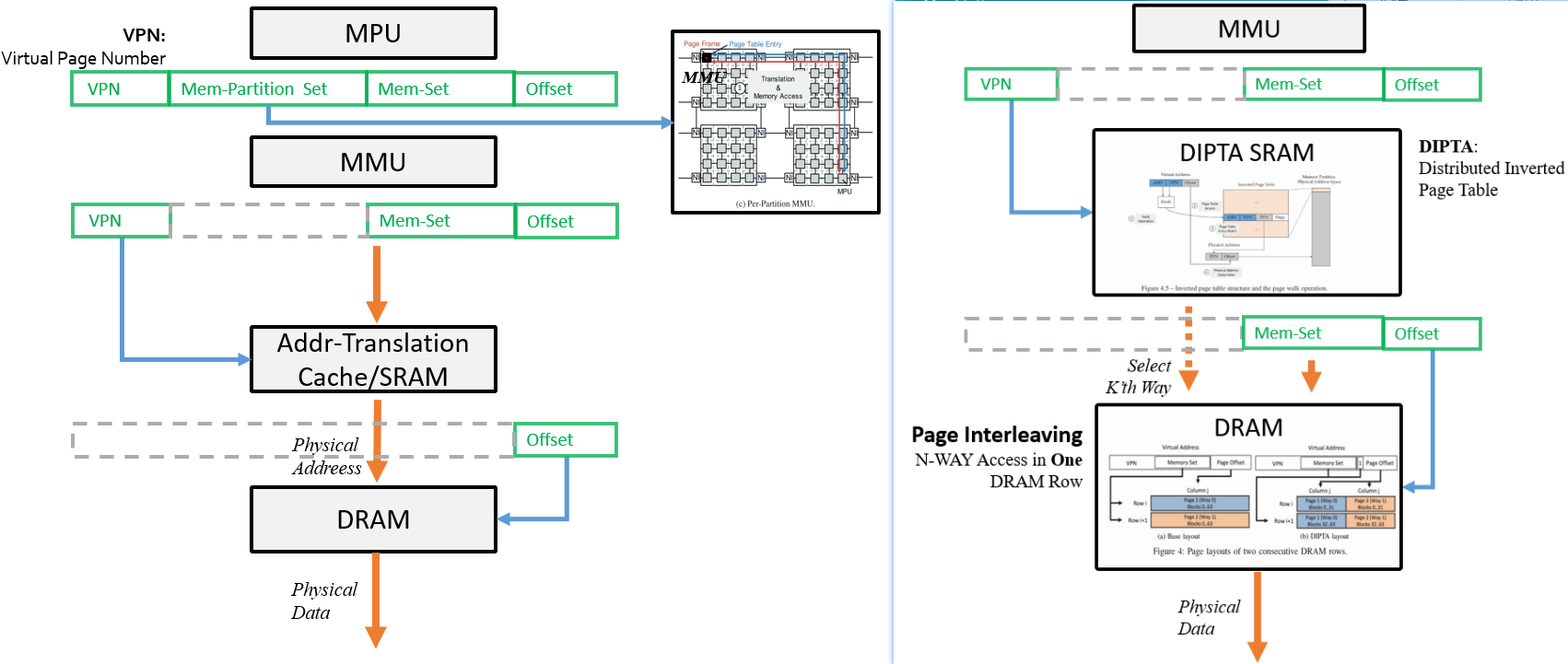
5. SRAM Design 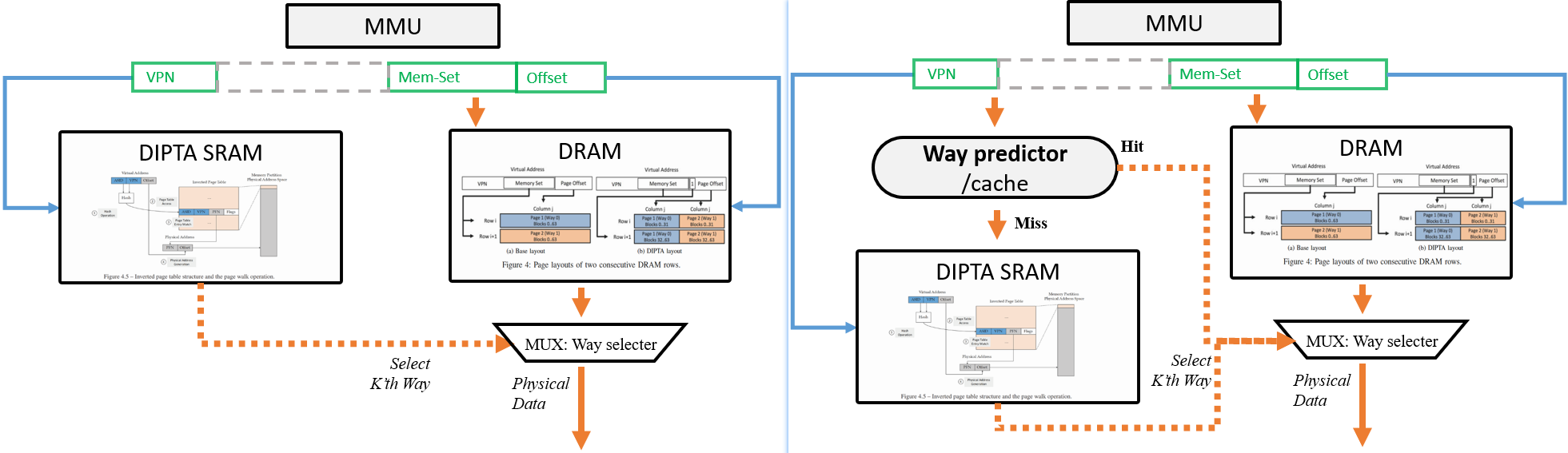
6. In-DRAM Design 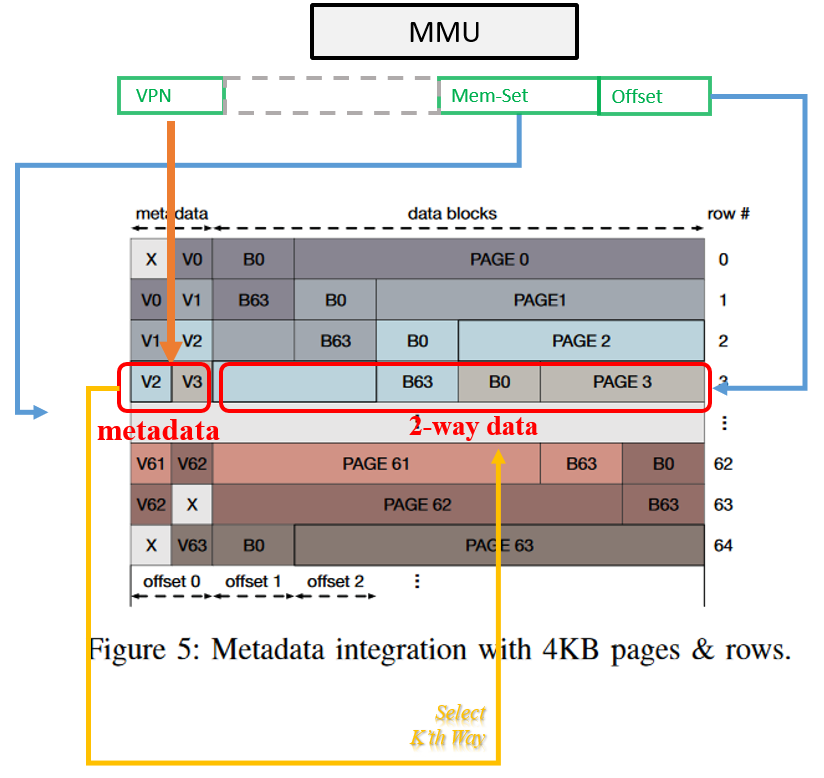
**Detail 1**: Speed up by limit multi-ways-check to one DRAM row access.
Change page layout(2) to make **cache-like** `j`-way k-set-assiciative DIPTA just search way in **one** DRAM row(3) to reduce lookup latency.
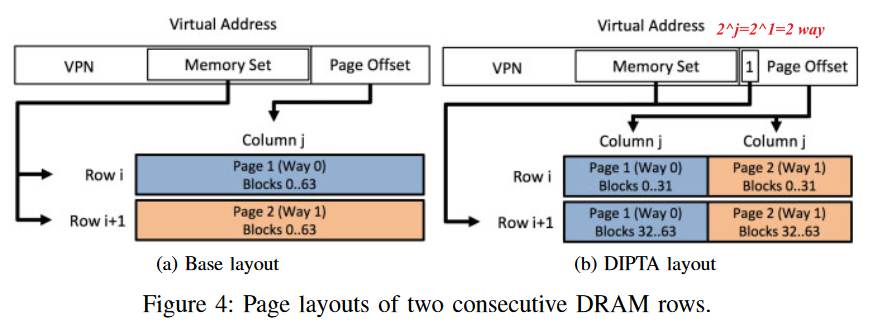
**Drawback**:
7. the NAT paper ether PACT'17 or first author's PhD thesis is hard to read and lack graph to explaination. Several few diagrams presentation are inconsistent to the paper writing.
8. Lack of further discussion about the cache-like DRAM kick-out when the way is conflict or memory full.
9. Lack of further discussion about the organization of conventional AT components such as the TLB
10. No proof provided of the design's effectiveness, e.g., way predictor, Or critical path analysis.
- is very similar to the VIPT L1 cache overlap v2p translation and cache index.
j*jmatrix transpose, each page is divided tojparts.- The target DRAM row is determined by the highest order bits of the part of the virtual address that used to identify the DRAM column (i.e., the page offset).
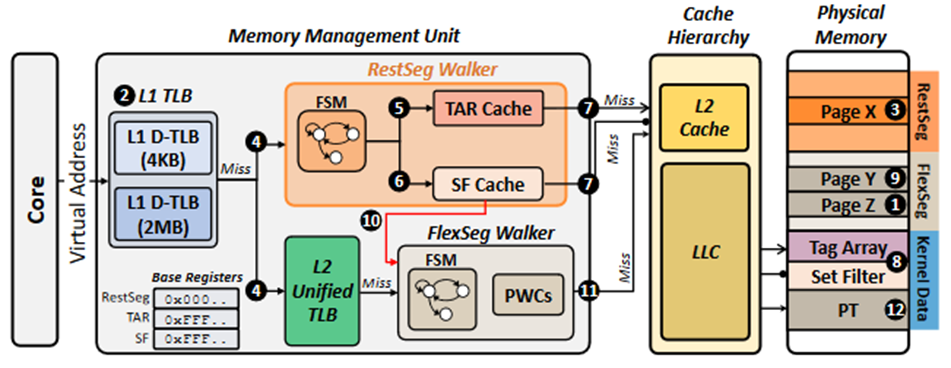
2 level fat-PT
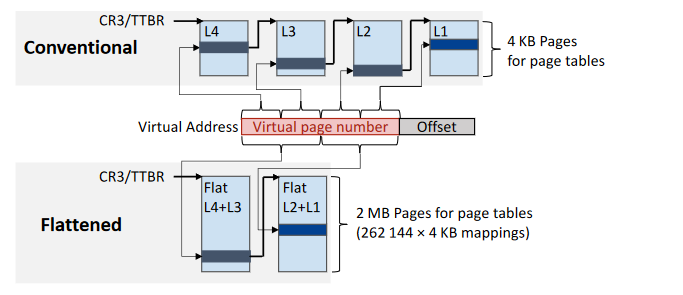 { width=50% }[^10]
{ width=50% }[^10]
Near-Memory Address Translation
- Restricting the virtual-to-physical mapping: determining the physical location of a virtual page based on a specific set of bits of the virtual address is considerably faster than accessing the x86-64 multi-level PT.
- and with a highly accurate way predictor
- translation and data fetch to proceed independently and in parallel. / fully overlap address translation with data fetch.
example:address translation requests in MMU
- PTW is performed by a dedicated hardware page table walker capable of performing multiple concurrent PTWs.
- Only L2 and LLC I guess, due to L1 typically does not store PT entries[^1], I think this is because VIPT L1 is in the front of DTLB.
参考文献
Guvenilir 和 Patt - 2020 - Tailored Page Sizes.pdf
https://blog.csdn.net/zmx1026/article/details/46471439
https://www.bilibili.com/video/BV1N3411y7Mr?spm_id_from=444.41.0.0
知乎: 高速缓存与一致性专栏索引 https://zhuanlan.zhihu.com/p/136300660
https://zhuanlan.zhihu.com/p/108425561
[^1]: Utopia: Fast and Efficient Address Translation via Hybrid Restrictive & Flexible Virtual-to-Physical Address Mappings
[^2]: Hash, Don’t Cache (the Page Table)
[^3]: ASPLOS’20: Elastic Cuckoo Page Tables: Rethinking Virtual Memory Translation for Parallelism
[^4]: Intel® 64 and IA-32 Architectures Software Developer’s Manual, Vol. 3: System Programming Guide 3A
[^5]: What are Super pages w.r.t Page tables ?
[^6]: Intel SDM /Section 4.5.4 /Figure 4-11. Formats of CR3 and Paging-Structure Entries with 4-Level Paging and 5-Level Paging
[^7]: Intel SDM /Section 4.5.4 /Figure 4-9. Linear-Address Translation to a 2-MByte Page using 4-Level Paging
[^8]: Arm Architecture Reference Manual for A-profile Architecture
[^9]: Linux Transparent Hugepage Support
[^10]: ASPLOS’22: Every Walk’s a Hit Making Page Walks Single-Access Cache Hits
[^11]: Pinning Page Structure Entries to Last-Level Cache for Fast Address Translation
[^12]: Address Translation Conscious Caching and Prefetching for High Performance Cache Hierarchy
[^14]: PACT’17 Near-Memory Address Translation
[^15]: J. F. Couleur and E. L. Glaser, “Shared-access data processing system,” 1968, US Patent 3,412,382. Available: http://www.google.com.ar/patents/US3412382
[^16]: Abhishek Bhattacharjee, Daniel Lustig, and Margaret Martonosi. 2011. Shared Last-level TLBs for Chip Multiprocessors. In Proceedings of the 2011 IEEE 17th International Symposium on High Performance Computer Architecture (HPCA’11).
[^17]: J. Bradley Chen, Anita Borg, and Norman P. Jouppi. 1992. A Simulation Based Study of TLB Performance. In Proceedings of the 19th Annual International Symposium on Computer Architecture (ISCA’92).
[^18]: Guilherme Cox and Abhishek Bhattacharjee. 2017. Efficient Address Translation for Architectures with Multiple Page Sizes. In Proceedings of the 22nd International Conference on Architectural Support for Programming Languages and Operating Systems
[^19]: M. Talluri, S. Kong, M. Hill, and D. Patterson, “Tradeoffs in Supporting Two Page Sizes,” ISCA, 1992.
[^20]: J. Navarro, S. Iyer, P. Druschel, and A. Cox, “Practical, Transparent Operating System Support for Superpages,” OSDI, 2002.
[^21]: B. Pham, J. Vesely, G. Loh, and A. Bhattacharjee, “Large Pages and Lightweight Memory Management in Virtualized Systems: Can You Have it Both Ways?,” MICRO, 2015.
[^22]: ISCA’15 Redundant Memory Mappings for Fast Access to Large Memories.
[^23]: Swapnil Haria, Mark D. Hill, and Michael M. Swift. 2018. Devirtualizing Memory in Heterogeneous Systems. In Proceedings of the 23rd International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS’18).
[^24]: Jayneel Gandhi, Arkaprava Basu, Mark D. Hill, and Michael M. Swift. 2014. Efficient Memory Virtualization: Reducing Dimensionality of Nested Page Walks. In Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO-47).
[^25]: “Observations and opportunities in architecting shared virtual memory for heterogeneous systems,” in Proceedings of the 2016 International Symposium on Performance Analysis of Systems and Software, 2016.
[^26]: T. W. Barr, A. L. Cox, and S. Rixner, “Translation caching: skip, don’t walk (the page table),” in Proceedings of the 2010 International Symposium on Computer Architecture, 2010.
[^27]: A. Bhattacharjee, “Large-reach memory management unit caches,” in Proceedings of the 2013 International Symposium on Microarchitecture, 2013.
[^28]: ISCA’13 Efficient Virtual Memory for Big Memory Servers